Deployment model
Akka services are distributed by design. You may run them locally, but they are built to operate across nodes (and even across cloud regions of multiple providers) without requiring changes to your code.
Service packaging
Services created with Akka components are composable. They can support agentic, transactional, analytics, edge, and digital twin systems. You may create a service with a single component or many.
Services are packed into a single binary. You can deploy it to various infrastructures including Platform as a Service (PaaS), Kubernetes, Docker Compose, virtual machines, bare metal, or edge computing environments.
Akka services cluster on their own. You do not need a service mesh. The clustering offers elasticity and resilience. Built-in features include data sharding, data rebalancing, traffic routing, and support for handling network partitions.
Deployment choices
Akka supports three deployment models. Behaviour remains consistent across them, and code changes are not needed when switching modes.
| Deployment Model | Description |
|---|---|
Development |
Developers can build, run, and test multi-service projects locally without needing cloud infrastructure. The Akka SDK provides persistence, clustering, service discovery, and integration features. This is the default when any service using Akka SDK is built. You may also run the local console for tracing and debugging. |
Akka clusters can be run on your infrastructure: virtual machines, containers, Platform as a Service (PaaS), edge, unikernels, or Kubernetes. You will need to configure routing, certificates, networking, and persistence yourself. Some PaaS systems may block network access, affecting clustering. In those cases, single-node operation is possible. |
|
Akka Automated Operations (AAO) (in your VPC or serverless) |
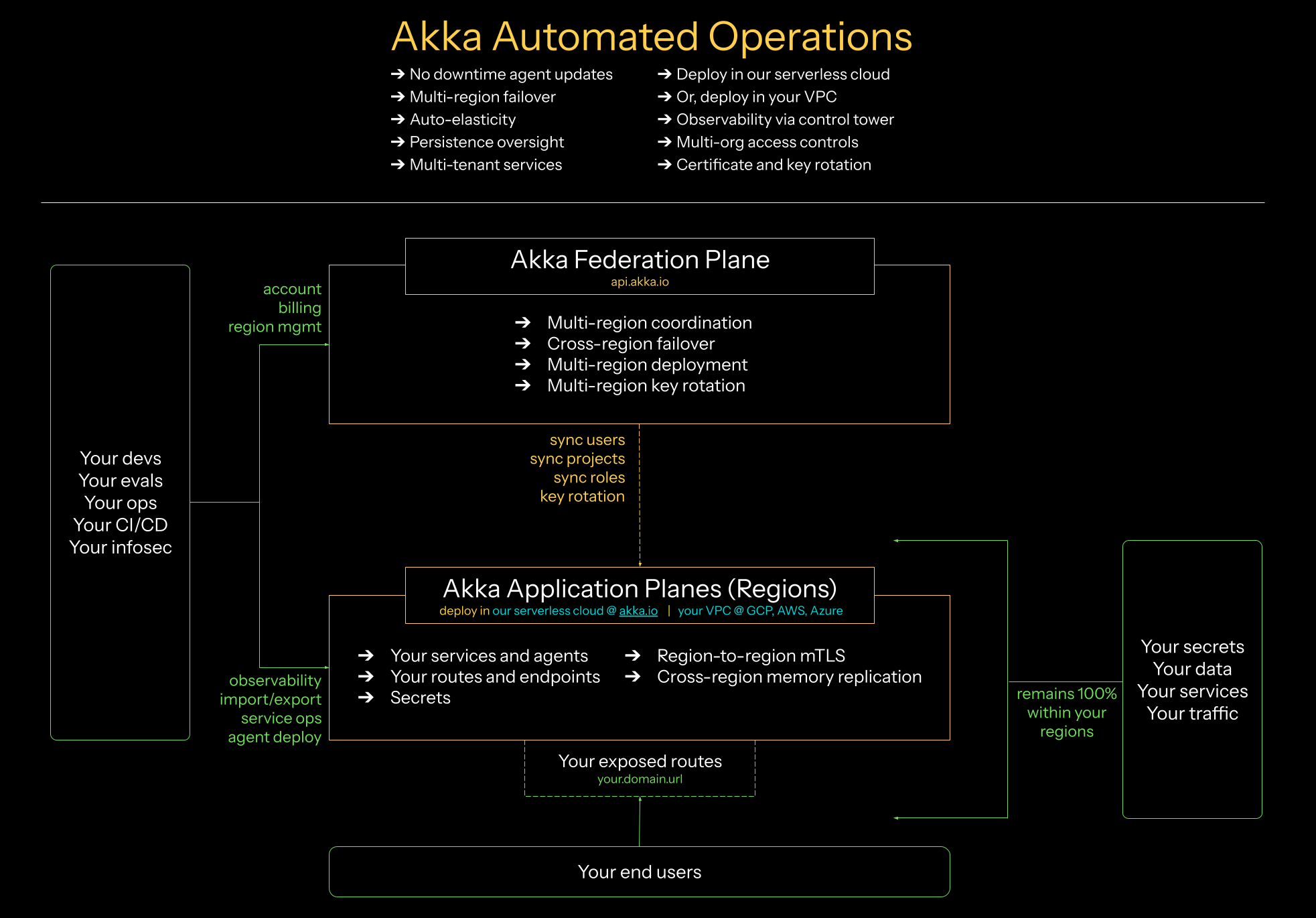
This optional product helps automate day 2 operations. It provides a global federation plane for managing federated regions, along with an application plane for running services in a secure way. Services can be deployed from the Akka CLI to either Akka’s serverless cloud or a privately managed VPC region. For enterprise users, a shared operations responsibility model is also available, where your team manages the underlying Kubernetes setup and Akka injects its specific components. AAO supports multi-region setups, including replication of durable state, failover arrangements, and data pinning for compliance needs. It provides elasticity based on observed traffic, memory auto-scaling, rolling upgrades without downtime, and access control at the organizational level. Observability is available through the Akka console or by exporting logs, metrics, and traces. AAO monitors traffic and system conditions and adjusts deployments to meet targets for availability and performance. |
Logical deployment model
Services
A service is the main unit of deployment. It includes all components as described in project structure and is packaged into a binary. Services may be started, stopped, paused, or scaled independently.
Projects
A project contains one or more services intended to be deployed together. It provides shared management capabilities. In AAO, projects also specify regions for deployment. The first region listed becomes the primary and initial deployment target when creating a project.
Physical deployment model
Akka services run in clusters. A cluster is a single Akka runtime spanning multiple nodes in a geographical location called a region.
With self-managed operations, a region maps to one cluster. With AAO, you can have multiple regions, each with its own clusters. These may be federated through a global federation plane. This enables service replication across regions and simplifies service discovery.
Regions in Akka Automated Operations
A region corresponds to a cloud provider’s location, such as AWS "US East." Akka spans availability zones and can scale multiple hyperscaler clouds. Projects specify the regions where they run. Each region receives a unique endpoint with region-specific DNS, much like services such as S3 or SQS. Container registries exist in all regions to reduce latency.
A set of regions is available for serverless deployments.
Additional Akka regions can be provisioned in your VPC on all major cloud providers, including the full setup along with monitoring and management.
Organizations that require more detailed control over the exact cloud setup can use a shared infrastructure responsibility model.
About Akka clustering
Clustering is integral to how Akka systems manage themselves. Services discover each other at startup and form clusters without manual setup. A connection to a single node is enough to join an existing cluster.
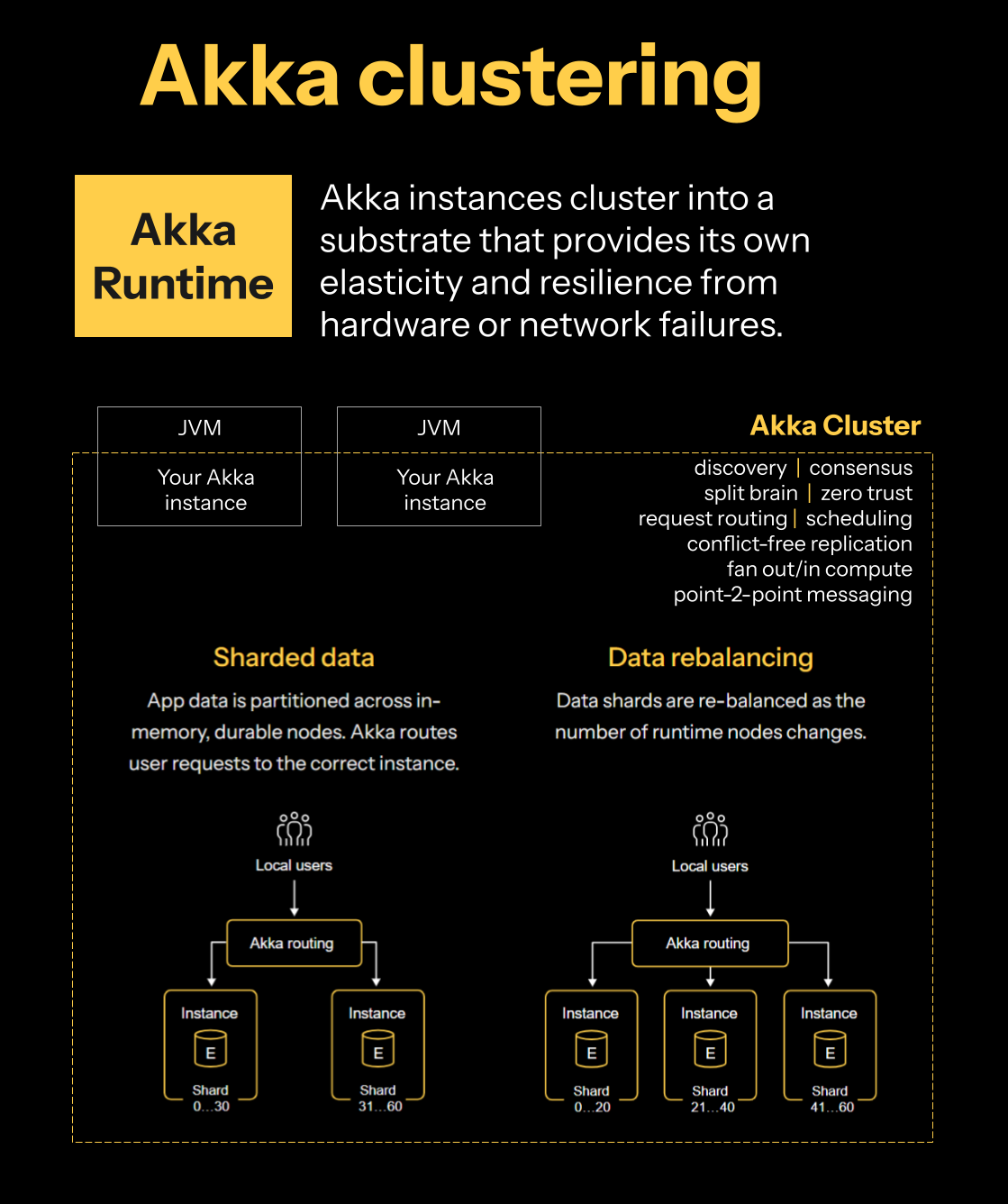
Clustering provides support for:
-
Elastic scaling
-
Failover
-
Traffic steering
-
Built-in discovery
-
Consensus and split-brain handling
-
Zero trust communication
-
Request routing and scheduling
-
Conflict-free replication
-
Point-to-point messaging
These capabilities enable stateful services to be resilient, durable, and capable of acting as their own orchestrators and in-memory caches.
Next steps
Now that you understand the overall architecture and deployment model of Akka you are ready to learn more about the Development process.
The following topics may also be of interest.