How to scale command-side and query-side independently
Not all nodes in an Akka Cluster need to be identical. When starting each process you can add some metadata to it to give that instance a special purpose. Node Roles ![]() in Akka Cluster will handle that metadata. The code (image) should still be the same for all roles, but it can select behavior at runtime based on the role configuration.
in Akka Cluster will handle that metadata. The code (image) should still be the same for all roles, but it can select behavior at runtime based on the role configuration.
This feature can be used to scale portions of your application independently. Let’s take for example the shopping cart Microservice from the tutorial:
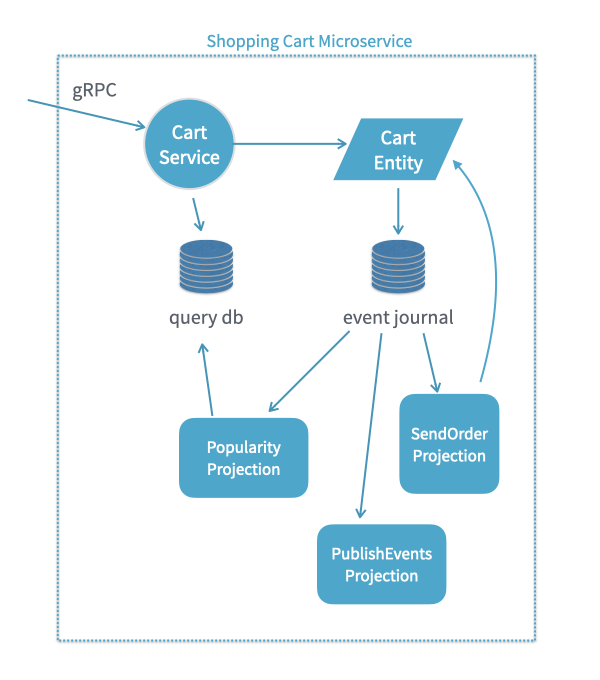
A single process running the shopping-cart-service (the dotted blue box in the diagram), has multiple sub-components. It:
-
serves gRPC traffic,
-
hosts
Cart Entity's (that is,EventSourcedBehavior's )
) -
runs three different projections
.
If there is a spike in traffic, the number of Cart Entity 's in memory may increase (or it may even be a high volume in regular traffic situations) so we would like to scale up the cluster. But, if the persistent entity is the bulk of the process load, it will be more efficient if the new nodes have fewer responsibilities.
For example:

This type of node, would not run the projections. Alternatively, we could also have nodes dedicated to only run projections and no persistent entities.
Tuning the Write-Side
To scale the persistent entities independently you need to make two changes:
-
configure the Sharding, so it only uses nodes with a certain role
-
set up the role in some nodes and deploy
Let’s see these two changes in more detail.
Configure the Sharding
When you initialize the Sharding of a persistent entity, as described in the tutorial, you may specify a role. Take for example the final code on the initialization of the persistent entity (from the tutorial):
- Java
-
src/main/java/shopping/cart/ShoppingCart.java:
public static void init(ActorSystem<?> system) { ClusterSharding.get(system) .init( Entity.of( ENTITY_KEY, entityContext -> ShoppingCart.create(entityContext.getEntityId()))); } - Scala
-
src/main/scala/shopping/cart/ShoppingCart.scala:
def init(system: ActorSystem[_]): Unit = { ClusterSharding(system).init(Entity(EntityKey)(entityContext => ShoppingCart(entityContext.entityId))) }
You can specify a role when declaring the entity ![]() :
:
- Java
-
src/main/java/shopping/cart/ShoppingCart.java:
public static void init(ActorSystem<?> system) { ClusterSharding.get(system) .init( Entity.of( ENTITY_KEY, entityContext -> { int i = Math.abs(entityContext.getEntityId().hashCode() % TAGS.size()); String selectedTag = TAGS.get(i); return ShoppingCart.create(entityContext.getEntityId(), selectedTag); }) .withRole("entity")); (1) }1 Define the role to be used for the ShoppingCartentities when initializingClusterSharding. - Scala
-
src/main/scala/shopping/cart/ShoppingCart.scala:
def init(system: ActorSystem[_]): Unit = { val behaviorFactory: EntityContext[Command] => Behavior[Command] = { entityContext => val i = math.abs(entityContext.entityId.hashCode % tags.size) val selectedTag = tags(i) ShoppingCart(entityContext.entityId, selectedTag) } ClusterSharding(system).init( Entity(EntityKey)(behaviorFactory).withRole("entity") ) (1) }1 Define the role to be used for the ShoppingCartentities when initializingClusterSharding.
Set up the role in some nodes
Then, when you deploy this new code you must make sure some nodes on your deployment include the role entity. These are the only nodes where the ShoppingCart entity will be run on.
You should have one Kubernetes Deployment for each role. In the deployment descriptor you can override the
akka.cluster.roles configuration with a Java system property or environment variable.
... -Dakka.cluster.roles.0=entity ...Tuning the Read-Side
To scale the projections independently you need to make two changes:
-
configure the Sharding, so it only uses nodes with a certain role
-
set up the role in some nodes and deploy
Let’s see these two changes in more detail.
Configure the Sharding
When you initialize the Sharded Daemon Processes ![]() for the projections, as described in the tutorial, you may specify a role. Take for example the final code on the initialization of the Sharded Daemon Process for the popularity projection (from the tutorial):
for the projections, as described in the tutorial, you may specify a role. Take for example the final code on the initialization of the Sharded Daemon Process for the popularity projection (from the tutorial):
- Java
-
src/main/java/shopping/cart/ItemPopularityProjection.java:
public static void init(ActorSystem<?> system, ItemPopularityRepository repository) { ShardedDaemonProcess.get(system) .initWithContext( (1) ProjectionBehavior.Command.class, "ItemPopularityProjection", 4, daemonContext -> { List<Pair<Integer, Integer>> sliceRanges = (2) EventSourcedProvider.sliceRanges( system, R2dbcReadJournal.Identifier(), daemonContext.totalProcesses()); Pair<Integer, Integer> sliceRange = sliceRanges.get(daemonContext.processNumber()); return ProjectionBehavior.create(createProjection(system, repository, sliceRange)); }, ShardedDaemonProcessSettings.create(system), Optional.of(ProjectionBehavior.stopMessage())); } - Scala
-
src/main/scala/shopping/cart/ItemPopularityProjection.scala:
ShardedDaemonProcess(system).initWithContext( (5) name = "ItemPopularityProjection", initialNumberOfInstances = 4, behaviorFactory = { daemonContext => val sliceRanges = (6) EventSourcedProvider.sliceRanges( system, R2dbcReadJournal.Identifier, daemonContext.totalProcesses) val sliceRange = sliceRanges(daemonContext.processNumber) ProjectionBehavior(projection(sliceRange)) }, ShardedDaemonProcessSettings(system), stopMessage = ProjectionBehavior.Stop)
You can specify a role when declaring the entity ![]() :
:
- Java
-
src/main/java/shopping/cart/ItemPopularityProjection.java:
public static void init( ActorSystem<?> system, JpaTransactionManager transactionManager, ItemPopularityRepository repository) { ShardedDaemonProcess.get(system) .init( ProjectionBehavior.Command.class, "ItemPopularityProjection", ShoppingCart.TAGS.size(), index -> ProjectionBehavior.create( createProjectionFor(system, transactionManager, repository, index)), ShardedDaemonProcessSettings.create(system).withRole("projection"), (1) Optional.of(ProjectionBehavior.stopMessage())); }1 Define the role to be used for the ItemPopularityProjectionwhen initializingShardedDaemonProcess. - Scala
-
src/main/scala/shopping/cart/ItemPopularityProjection.scala:
def init( system: ActorSystem[_], repository: ItemPopularityRepository): Unit = { ShardedDaemonProcess(system).init( name = "ItemPopularityProjection", ShoppingCart.tags.size, index => ProjectionBehavior(createProjectionFor(system, repository, index)), ShardedDaemonProcessSettings(system).withRole("projection"), (1) Some(ProjectionBehavior.Stop)) }1 Define the role to be used for the ItemPopularityProjectionwhen initializingShardedDaemonProcess.
Set up the role in some nodes
Then, when you deploy this new code you must make sure some nodes on your deployment include the role projection. These are the only nodes where the ItemPopularityProjection projection daemon processes will be run on.
You should define the roles in the deployment descriptor as described for the entity role above.
... -Dakka.cluster.roles.0=projection ...