Enabling OpenTracing in your app
Entities such as actors, streams, or HTTP endpoints need to be configured for tracing. There are also various options around tracing, such as trace sampling, naming, or tagging.
Actor configuration
Actors need to be enabled for tracing, similar to metrics and events. This is an extension of the actor configuration, with a traceable setting that can be enabled for any actor selection.
For example, actors can be selected by class or path and then enabled as traceable, such as in the following configuration:
cinnamon.akka {
actors {
"com.example.a.b.*" {
report-by = class
traceable = on
}
"/user/x/*" {
report-by = class
traceable = on
}
}
}Akka persistent actor configuration
Akka persistent actors need to be enabled for tracing, similar to metrics and events. This is an extension of the Persistent actor configuration with a traceable setting that can be enabled for any actor or persistent entity selection.
For example, persistent entities can be selected by class or path and then enabled as traceable, such as in the following configuration:
cinnamon.akka {
persistence.entities {
"/system/sharding/EntityFooName/*" {
report-by = group
traceable = on
}
}
}When Akka persistent actor tracing is enabled it will produce persistence specific spans such as waiting-permit, receive-command, stash-command, recovery and persist-event. Below is an image of what a persistent entity trace can look like when it’s enabled:

System messages
Akka system messages (special internal messages for managing actors) can also be traced. This is off by default, but can be enabled with this configuration:
cinnamon.opentracing {
akka {
trace-system-messages = on
}
}Akka scheduler configuration
Context propagation
By default, OpenTracing context will be propagated with scheduleOnce.
If you use scheduleOnce in a way that it forms cycles it will create potentially infinite traces. In order to break such infinite traces disable the connect-traces setting.
Span creation
By default, no spans will be created for the runnable execution time passed to scheduleOnce. Whether to build spans or not also depends on the Auto trace setting. Here is the decision table:
| Auto trace | The build-spans setting | Build spans | Comment |
|---|---|---|---|
| off | off | no | By default no spans will be built. |
| off | on | yes | The build-spans setting enables span creation. |
| on | on/off | yes | Auto trace enables span creation for active traces regardless of build-spans setting. |
- Reference
-
cinnamon.opentracing { akka.scheduler { schedule-once { # Whether to connect traces for asynchronous calls scheduled with the Akka Scheduler scheduleOnce. # Turn it off to disconnect possibly infinite traces. connect-traces = on # Whether to build spans for the execution of the Runnable passed to the Akka Scheduler scheduleOnce. # Note that it will create spans even if build-spans is off when auto-trace is enabled and it's an active trace. build-spans = off } } }
Akka Streams configuration
Akka Streams need to be enabled for tracing, similar to metrics. This is an extension of the Akka Stream configuration, with a traceable setting that can be enabled when configuring streams for instrumentation.
For example, streams can be selected using configuration based on the materialization call site and then enabled as traceable, such as in the following config:
cinnamon.akka {
streams {
"example.streams.a.A.*" {
report-by = name
traceable = on
}
}
}Or streams can be enabled as traceable using the Instrumented attribute, such as in the following example:
- Scala
-
import com.lightbend.cinnamon.akka.stream.CinnamonAttributes._ Source.single(0) .map(_ + 1) .to(Sink.ignore) .instrumented(name = "my-stream", traceable = true) .run() - Java
-
import com.lightbend.cinnamon.akka.stream.CinnamonAttributes; Source.single(0) .map(x -> x + 1) .to(Sink.ignore()) .addAttributes( CinnamonAttributes.isInstrumented() .withReportByName("my-stream") .setTraceable() .attributes()) .run(system);
Alpakka Kafka configuration
OpenTracing contexts are automatically propagated for Alpakka Kafka producers and consumers. The trace context is injected into the headers of producer records and extracted again when records are consumed, allowing traces to be connected across producers and consumers of Kafka topics. While trace context propagation is enabled by default, trace spans need to be enabled explicitly, similar to other instrumented components. Trace spans for consumers and producers are enabled using configuration:
cinnamon.opentracing {
alpakka.kafka {
consumer-spans = on
producer-spans = on
}
}Below is an image of what a cross-service trace can look like for Alpakka Kafka when producer and consumer spans are enabled:

It may also be useful to have a consumer span active for the downstream processing keeping the tracing context available. For example, when “context-only” spans have to be disabled because they are not supported by some tracers such as ElasticAPM. See OpenTracing compatibility for more details. In order to enable Alpakka Kafka consumer span continuations use the next setting:
cinnamon.opentracing {
alpakka.kafka {
consumer-spans = on
consumer-continuations = on
}
}Alpakka Kafka tracing can be used with or without Akka Streams being enabled for tracing. Below is an image of what a cross-service trace can look like with both Alpakka Kafka and Akka Streams tracing enabled:
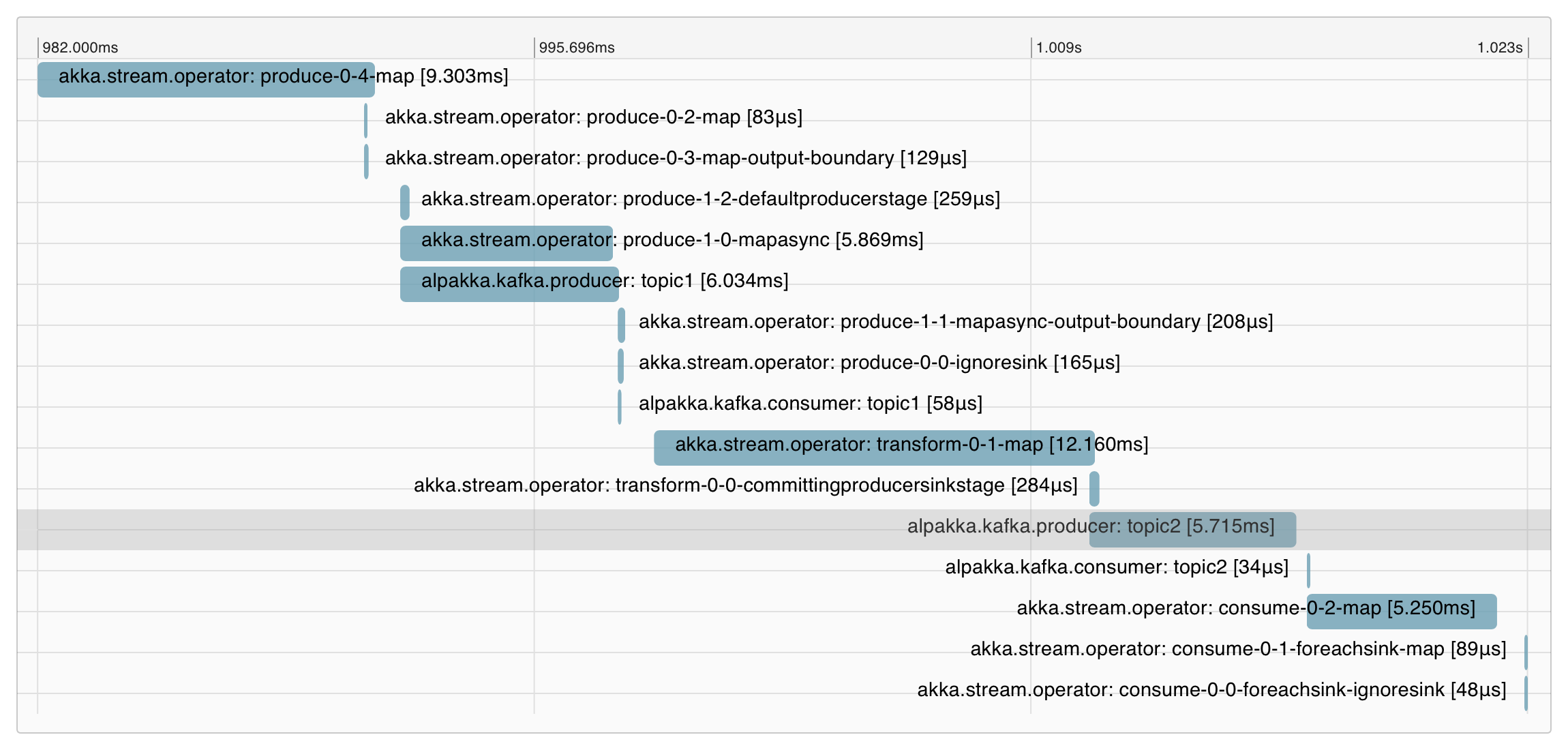
If needed, tracing (including the automatic trace context propagation) can be disabled for Alpakka Kafka producers or consumers or both, using the following configuration:
cinnamon.opentracing {
alpakka.kafka {
trace-consumers = off
trace-producers = off
}
}Akka HTTP configuration
Akka HTTP endpoints need to be enabled for tracing, similar to metrics. This is an extension of the Akka HTTP configuration, with a traceable setting that can be enabled for any endpoint selection.
For example, endpoint paths can be selected using a wildcard and then enabled as traceable, such as in the following configuration:
cinnamon.akka.http {
clients {
"*:*" {
paths {
"*" {
traceable = on
}
}
}
}
servers {
"*:*" {
paths {
"*" {
traceable = on
}
}
}
}
}Akka HTTP internal actors
An Akka HTTP server also creates actors under the /user guardian. If you have enabled actor tracing with a /user/* selection, then internal Akka HTTP and Akka Streams actors will also appear in traces. You can select actors by package instead, to only trace application actors. Or you can exclude the internal actor packages from a /user/* selection, such as in the following configuration:
cinnamon.akka {
actors {
"/user/*" {
excludes = ["akka.http.*", "akka.stream.*"]
report-by = class
traceable = on
}
}
}Akka HTTP span context propagation
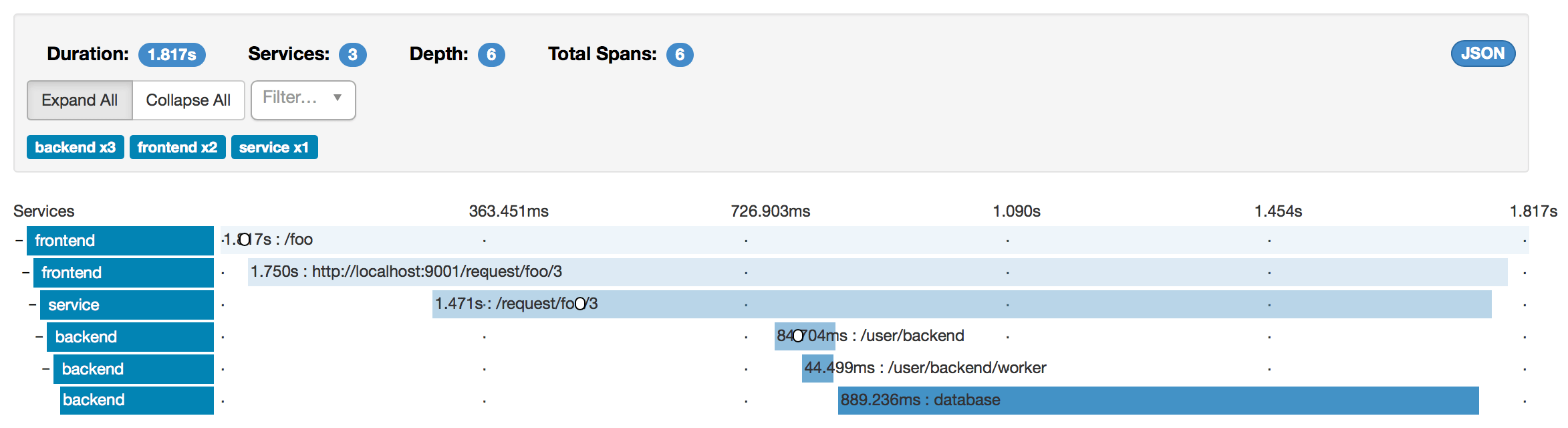
If tracing is enabled, Lightbend Telemetry will automatically handle propagation of existing span contexts. For Akka HTTP, tracing means that the context is extracted from a trace span and injected into the headers of an outgoing HTTP Request (client-side), and extracting the context from an incoming HTTP Request to create a span (server-side).
Below is an image of what a cross-service trace can look like when using the trace propagation feature:
Scala Futures
Active traces will be automatically propagated through Scala Futures, but scheduled Futures or callbacks will not be automatically represented as trace spans. To enable tracing of Futures, there is a naming API to indicate Futures or Future callbacks that should be traced and to specify the trace span operation name.
For example, there is a named alternative to Future.apply which allows scheduled Futures to be traced:
- Scala
-
// this Future is not traceable val future = Future { "compute all the things" } import com.lightbend.cinnamon.scala.future.named._ // this Future is traceable and named "compute" val tracedFuture = FutureNamed("compute") { "compute all the things" }
There are also named alternatives for the callback operations, which are added implicitly as extension methods on Future. For example, to name and trace a mapped transform operation between actors, the mapNamed method can be used in place of map:
- Scala
-
import com.lightbend.cinnamon.scala.future.named._ val foo = tracedActor("foo") val bar = tracedActor("bar") val future = foo ? message val transformed = future.mapNamed("transform") { value => transform(value) } transformed.pipeTo(bar)
This transformation will then show up as its own trace span, between the actor spans, such as in this trace:

Cached Scala Futures
Cinnamon tracks two contexts for Scala Futures: the context where callbacks are added, and the context where the underlying Promise is completed. For tracing, the completion context is preferred so that traces follow the dataflow. If Futures are cached and then reused in subsequent traces, any callbacks will be connected with the original trace context. In this case, the completion context can be disabled for a Future by using the disableContext method included in the nameable Future extensions:
- Scala
-
import com.lightbend.cinnamon.scala.future.named._ traceSpan("one") { // future is created within the first trace context val future = FutureNamed("compute") { "compute all the things" } // the future is cached to reuse the result // but will not connect to this first trace context cached += "foo" -> future.disableContext() } traceSpan("two") { // this second trace context will be used for future callbacks cached("foo").mapNamed("something")(doSomething) }
Java Futures
Active traces will be automatically propagated through Java CompletableFutures, but scheduled CompletableFutures or CompletionStage callbacks will not be automatically represented as trace spans. To enable tracing of CompletableFutures, there is a naming API to indicate CompletableFutures or CompletionStage callbacks that should be traced and to specify the trace span operation name.
For example, NameableCompletableFuture has a named alternative to CompletableFuture.supplyAsync which allows scheduled CompletableFutures to be traced:
- Java
-
import com.lightbend.cinnamon.java.future.NameableCompletableFuture; import java.util.concurrent.CompletableFuture; // this CompletableFuture is not traceable CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> "compute all the things"); // this CompletableFuture is traceable and named "compute" CompletableFuture<String> tracedFuture = NameableCompletableFuture.supplyAsyncNamed("compute", () -> "compute all the things");
There is also a NameableCompletionStage with named alternatives for the CompletionStage callback operations. For example, to name and trace a transform operation between actors the thenApplyNamed method can be used in place of thenApply:
- Java
-
import akka.actor.ActorRef; import akka.pattern.Patterns; import java.util.concurrent.CompletionStage; import static com.lightbend.cinnamon.java.future.NameableCompletionStage.nameable; final ActorRef foo = tracedActor.named("foo"); final ActorRef bar = tracedActor.named("bar"); CompletionStage<Object> future = Patterns.ask(foo, message, timeout); CompletionStage<Object> transformed = nameable(future).thenApplyNamed("transform", value -> transform.apply(value)); Patterns.pipe(transformed, system.dispatcher()).to(bar, sender);
This transformation will then show up as its own trace span, between the actor spans, such as in this trace:

Cached Java Futures
Cinnamon tracks two contexts for Java CompletableFutures: the context where callbacks are added, and the context where the future is completed. For tracing, the completion context is preferred so that traces follow the dataflow. If CompletionStages are cached and then reused in subsequent traces, any callbacks will be connected with the original trace context. In this case, the completion context can be disabled for a CompletionStage or CompletableFuture by using the disableContext method included in the nameable extensions:
- Java
-
import com.lightbend.cinnamon.java.future.NameableCompletableFuture; import com.lightbend.cinnamon.java.future.NameableCompletionStage; import static com.lightbend.cinnamon.java.future.NameableCompletionStage.nameable; traceSpan( "one", () -> { // future is created within the first trace context CompletionStage<String> future = NameableCompletableFuture.supplyAsyncNamed("compute", () -> "compute all the things"); // the future is cached to reuse the result // but will not connect to this first trace context cached.put("foo", NameableCompletionStage.disableContext(future)); }); traceSpan( "two", () -> { // this second trace context will be used for future callbacks nameable(cached.get("foo")).thenApplyNamed("something", value -> doSomething(value)); });
Trace span names
By default, Cinnamon creates trace span names with two parts, the operation and the resource or entity being traced:
<operation>: <resource>
Here are some example span names for an Akka HTTP request, an Akka Actor message receive, and an Akka Stream operator:
"akka.http.server.request: GET /hello/<String>"
"akka.actor.receive: /user/actor"
"akka.stream.operator: my-stream-0-1-map"To exclude the resource name from trace span names and only have the static operation name, you can disable the following configuration setting:
cinnamon.opentracing {
span.name {
include-resource = off
}
}You can also modify the operation names used for trace spans via configuration. For example, to change the operation name used for actor receive spans, you can use the following configuration:
- Example
-
cinnamon.opentracing { spans { akka.actor.receive.operation = "actor" } } - Reference
-
cinnamon.opentracing { span.name { # Whether to include resource names in full span names include-resource = on } # Tags to add to all trace spans span.tags {} # Settings for trace span building spans { akka.actor { receive { operation = "akka.actor.receive" tags { component = "akka.actor" span.kind = "consumer" } } system-message { operation = "akka.actor.system-message" tags { component = "akka.actor" span.kind = "consumer" } } } akka.persistence { receive-command { operation = "akka.persistence.receive-command" tags { component = "akka.persistence" span.kind = "consumer" } } stash-command { operation = "akka.persistence.stash-command" tags { component = "akka.persistence" span.kind = "consumer" } } persist-event { operation = "akka.persistence.persist-event" tags { component = "akka.persistence" span.kind = "consumer" } } recovery { operation = "akka.persistence.recovery" tags { component = "akka.persistence" span.kind = "consumer" } } waiting-permit { operation = "akka.persistence.waiting-permit" tags { component = "akka.persistence" span.kind = "consumer" } } } akka.scheduler { schedule-once { operation = "akka.scheduler.schedule-once" tags { component = "akka.scheduler" span.kind = "consumer" } } } akka.stream { operator { operation = "akka.stream.operator" tags { component = "akka.stream" span.kind = "consumer" } } boundary { operation = "akka.stream.boundary" tags { component = "akka.stream" span.kind = "consumer" } } buffer { operation = "akka.stream.buffer" tags { component = "akka.stream" span.kind = "consumer" } } context-propagation { operation = "akka.stream.context-propagation" tags { component = "akka.stream" span.kind = "consumer" } } } alpakka.kafka { consumer { operation = "alpakka.kafka.consumer" tags { component = "alpakka.kafka" span.kind = "consumer" peer.service = "kafka" } } producer { operation = "alpakka.kafka.producer" tags { component = "alpakka.kafka" span.kind = "producer" peer.service = "kafka" } } } akka.http { client { operation = "akka.http.client.request" tags { component = "akka.http" span.kind = "client" } } server { operation = "akka.http.server.request" tags { component = "akka.http" span.kind = "server" } } } } }
These settings are defined in the reference.conf. You only need to specify any of these settings when you want to override the defaults.
Trace span tags
Cinnamon will automatically include tags for trace spans, both static tags—that are always the same for a particular type of span—and dynamic tags—which are based on the traced entity, or requests, messages, or elements received.
Static tags
The static tags for a trace span can be configured, and extra tags can be added via configuration. For example, to change the provided component tag for an Akka HTTP server request, and to add a new tag named span.type set to web, we can use the following configuration:
- Example
-
cinnamon.opentracing { spans { akka.http.server { tags { component = "akka.http.server" span.type = "web" } } } } - Reference
-
cinnamon.opentracing { span.name { # Whether to include resource names in full span names include-resource = on } # Tags to add to all trace spans span.tags {} # Settings for trace span building spans { akka.actor { receive { operation = "akka.actor.receive" tags { component = "akka.actor" span.kind = "consumer" } } system-message { operation = "akka.actor.system-message" tags { component = "akka.actor" span.kind = "consumer" } } } akka.persistence { receive-command { operation = "akka.persistence.receive-command" tags { component = "akka.persistence" span.kind = "consumer" } } stash-command { operation = "akka.persistence.stash-command" tags { component = "akka.persistence" span.kind = "consumer" } } persist-event { operation = "akka.persistence.persist-event" tags { component = "akka.persistence" span.kind = "consumer" } } recovery { operation = "akka.persistence.recovery" tags { component = "akka.persistence" span.kind = "consumer" } } waiting-permit { operation = "akka.persistence.waiting-permit" tags { component = "akka.persistence" span.kind = "consumer" } } } akka.scheduler { schedule-once { operation = "akka.scheduler.schedule-once" tags { component = "akka.scheduler" span.kind = "consumer" } } } akka.stream { operator { operation = "akka.stream.operator" tags { component = "akka.stream" span.kind = "consumer" } } boundary { operation = "akka.stream.boundary" tags { component = "akka.stream" span.kind = "consumer" } } buffer { operation = "akka.stream.buffer" tags { component = "akka.stream" span.kind = "consumer" } } context-propagation { operation = "akka.stream.context-propagation" tags { component = "akka.stream" span.kind = "consumer" } } } alpakka.kafka { consumer { operation = "alpakka.kafka.consumer" tags { component = "alpakka.kafka" span.kind = "consumer" peer.service = "kafka" } } producer { operation = "alpakka.kafka.producer" tags { component = "alpakka.kafka" span.kind = "producer" peer.service = "kafka" } } } akka.http { client { operation = "akka.http.client.request" tags { component = "akka.http" span.kind = "client" } } server { operation = "akka.http.server.request" tags { component = "akka.http" span.kind = "server" } } } } }NoteThese settings are defined in the
reference.conf. You only need to specify any of these settings when you want to override the defaults.
Global static tags
Static tags can also be configured for all trace spans created by Cinnamon. For example, this configuration sets a custom environment tag to staging:
- Example
-
cinnamon.opentracing { span.tags { environment = "staging" } }
String representations
Cinnamon will automatically include tags in a trace span for objects like the message received by an actor or the element processed by a stream operator. By default, the toString of the object is used, but this behavior is configurable. To switch to using just the class name for these objects, use the following configuration:
cinnamon.opentracing {
object-formatter = object-to-class-name
}Custom object formatter
A custom object formatter, for string representations of objects in trace spans, can also be configured. An ObjectFormatter class needs to be implemented and configuration added to use this formatter.
For example, we can create a CustomObjectFormatter class, implementing the formatToString method:
import com.lightbend.cinnamon.opentracing.ObjectFormatter
class CustomObjectFormatter extends ObjectFormatter {
override def formatToString(someObject: Object): String = {
String.valueOf(someObject).toUpperCase
}
}We can then configure the OpenTracing integration to use this formatter with:
cinnamon.opentracing {
object-formatter = custom-object-formatter
custom-object-formatter {
formatter-class = "opentracing.api.sample.CustomObjectFormatter"
}
}Add HTTP headers as tags
Available since Cinnamon 2.13.0
Cinnamon can automatically include specified HTTP headers as trace span tags. For example, to automatically add a tag on HTTP server request spans based on a particular correlation id header, the following configuration can be used:
- Example
-
cinnamon.opentracing { http { tag-headers += "X-Correlation-Id" } }
Debug traces (forced sampling)
Traces that begin with an HTTP request can have a “debug mode” enabled using an HTTP header. When a trace debug header is configured and present on an HTTP request, then the request will have a sampling priority tag added, to hint that this trace should be force sampled. For the default tracer, used for Jaeger and Zipkin reporters, the debug flag will also be enabled—which flags the trace to survive all downsampling that might happen in the trace collection pipeline. The value of the trace debug header can be used as a correlation identifier as it will be added as a trace tag.
To enable debug traces, set the name of the debug header in configuration:
- Example
-
cinnamon.opentracing { http { debug-header = "Trace-Debug" } }
This header can then be set on HTTP requests to force sample traces and provide a correlation identifier for the trace:
- Example
-
"Trace-Debug" -> "some-correlation-id"
When using the default tracer (based on the Jaeger client) then the built-in debug mode via HTTP headers can also be used—by using the jaeger-debug-id header rather than configuring a custom header.
Auto trace
Cinnamon will only create trace spans for entities that have been enabled for tracing. To connect together traces across any intermediary asynchronous boundaries which are not enabled for tracing, Cinnamon will use a “pass-through” mode—where the trace context is passed through without any trace spans being created. It’s also possible to enable “auto tracing” which will automatically create trace spans for the intermediate steps, whenever these occur within a currently active and sampled trace. Note that enabling auto traces can increase the number of trace spans significantly, and will also trace both user code and framework internals. To enable auto traces, use this configuration setting:
cinnamon.opentracing {
auto-trace = on
}To only enable auto traces when within a debug trace use the following configuration instead:
cinnamon.opentracing {
auto-trace-when-debug = on
}