Akka Stream configuration
Streams need to be selected for telemetry. To avoid any unwanted impact on application performance, you need to decide which streams in your system are instrumented. The different methods for selecting streams for instrumentation are covered in the next section.
Streams are not instrumented automatically, but must have instrumentation enabled explicitly.
Selecting streams for instrumentation
Streams can be selected for instrumentation in one of three ways:
- Based on the name of the stream.
- By adding the instrumented attribute to a stream.
- Based on the materialized code location of the stream.
Using materialized code location can result in a significant performance hit due to Telemetry having to do a call-site lookup for every stream materialization. It is recommended that you instrument using stream names or the instrumented attribute.
Selection using stream name
Streams can be named via the named method, as shown in the following examples:
- Scala
-
// example stream: named stream that will be selected for instrumentation by name Source.single(0) .map(_ + 1) .to(Sink.ignore) .named("my-stream") .run() - Java
-
// example stream: named stream that will be selected for instrumentation by name Source.single(0).map(x -> x + 1).to(Sink.ignore()).named("my-stream").run(materializer);
Given one or more named streams like the above example, they can be selected for instrumentation with the following config:
cinnamon.akka {
streams {
"name:my-stream" {
report-by = name
}
}
}Streams can be given multiple names, allowing you to include and exclude by names where appropriate. The following code demonstrates assigning multiple names to a stream:
- Scala
-
// example of two streams, one with multiple names // this stream WILL be instrumented (name:my-stream) Source.single(0) .map(_ + 1) .to(Sink.ignore) .named("my-stream") .run() // this stream will NOT be instrumented (name:my-stream, excludes = name:exclude-me) Source.single(0) .map(_ + 1) .to(Sink.ignore) .named("my-stream") .named("exclude-me") .run()
Based on the above code, you could include all streams named my-stream, but exclude all streams also named exlude-me with the following config:
cinnamon.akka {
streams {
"name:my-stream" {
report-by = name
excludes = "name:exclude-me"
}
}
}Selection using instrumented attribute
Streams can be selected for instrumentation programmatically by attaching a special stream [Attribute][attribute] to the runnable graph.
Cinnamon provides an Instrumented attribute for specifying telemetry settings directly on a stream. For a list of the various arguments and methods for programatically specifying configuration options, see the API documentation.
First import the CinnamonAttributes class:
- Scala
-
import com.lightbend.cinnamon.akka.stream.CinnamonAttributes - Java
-
import com.lightbend.cinnamon.akka.stream.CinnamonAttributes;
You can then attach the Instrumented attribute to a stream to configure the telemetry settings:
- Scala
-
Source.single(0) .map(_ + 1) .to(Sink.ignore) .named("my-stream") .addAttributes(CinnamonAttributes.instrumented(reportByName = true)) .run() - Java
-
Source.single(0) .map(x -> x + 1) .to(Sink.ignore()) .named("my-stream") .addAttributes(CinnamonAttributes.instrumentedByName()) .run(materializer);
Additional programmatic features are discussed in the programmatic stream instrumentation section.
Selection using materialized code location
You can specify the code location where the stream is materialized by specifying the full method, or specifying an enclosing class or package using wildcards.
Selecting streams based on their code location relies on checking the call-site for every stream materialization in your system. Checking the call stack is relatively expensive, for better performance, you should consider using name or attribute based selection.
The following example shows a configuration block to instrument streams by specifying a full method:
cinnamon.akka {
streams {
"example.streams.a.A.method" {
report-by = name
}
"example.streams.a.A$B.method" {
report-by = name
}
}
}A * wildcard can also be used at the end of a selection, after a delimiter, to select all methods within the given package or class. The following are valid stream selections for methods in a package, methods in a class, or for methods in inner classes, where streams are materialized:
"example.streams.a.*"
"example.streams.a.A.*"
"example.streams.a.A$*"
"example.streams.a.A$B.*"Settings can be applied to each configured stream selection. The main setting is report-by, for enabling instrumentation and deciding how the selected streams will report metrics.
Selection excludes
The above sections detail how to specify streams to be included in instrumentation, telemetry also supports the explicit exclusion of streams via the excludes configuration directive. Streams can be excluded based on code location and stream name.
The following example excludes streams based on a wildcard code location:
cinnamon.akka {
streams {
"example.streams.a.*" {
report-by = name
excludes = ["example.streams.a.B.*", "example.streams.a.b.*"]
}
}
}The above configuration enables telemetry for all streams materialized in the example.streams.a package, apart from the example.streams.a.B class and those streams materialized in the example.streams.a.b sub-package.
The following example excludes streams based on their name:
cinnamon.akka {
streams {
"example.streams.a.*" {
report-by = instance
excludes = "name:my-stream"
}
}
}The above also demonstrates that you can mix code location and name based selectors when including and excluding streams.
Report-by settings
Instrumentation is enabled for a stream selection using the report-by setting. There are two main ways to report metrics: either metrics are aggregated by stream name—using the Name attribute of the stream graph—or metrics are reported for individual stream instances—using a unique identifier created by the materializer, such as flow-0.
Here’s an example configuration that enables instrumentation for several streams:
cinnamon.akka {
streams {
"example.streams.a.A.method" {
report-by = name
}
"example.streams.a.B.*" {
report-by = instance
}
"example.streams.a.b.*" {
report-by = name
}
"example.streams.a.A$B.*" {
report-by = [name, instance]
}
}
}Streams that are reported by instance should be carefully selected, to avoid too many unique metric identifiers.
Streams that are reported by name create aggregated metrics for all streams with the same name.
To use report-by-name the runnable graph needs to be named, such as with this stream:
Source.single(0).map(_ + 1).to(Sink.ignore).named("my-stream").run()Reporting by name requires a Name attribute to be attached to the whole runnable graph, including the sinks.
If the name attribute has not been applied to the runnable graph, then you will see a logged warning like this: Stream [flow-0] materialized at [example.caller] is configured to report by name attribute, but there is no name attribute attached to the graph.
Programmatic stream instrumentation
The selection using instrumented attribute section demonstrated basic use of addAttributes with the CinnamonAttributes class. This section discusses additional convenience methods provided by telemetry.
For Scala, there is an implicit extension method available to provide a more convenient way to enable instrumentation, similar to the named method available on graphs. When configuring report-by-name, you can also enable this by providing the name directly.
- Scala
-
import com.lightbend.cinnamon.akka.stream.CinnamonAttributes.GraphWithInstrumented Source.single(0) .map(_ + 1) .to(Sink.ignore) .instrumented(name = "my-stream") .run()
Instrumented runWith
When using the Instrumented attribute to configure instrumentation settings for streams, the attribute needs to be applied to the whole runnable graph (including the sinks). This means that the Instrumented attribute can’t be used in conjunction with the runWith method on sources. Also note that source.runWith(sink) is equivalent to source.toMat(sink)(Keep.right).run() while source.to(sink).run() is equivalent to source.toMat(sink)(Keep.left).run(). That is, runWith keeps the materialized value from the sink, while to/run keeps the materialized value from the source.
To make it easier to instrument streams that currently use runWith to connect the sink, and make use of the returned materialized value, Cinnamon provides instrumentedRunWith helper methods. For Scala, this is provided as an implicit extension method. For Java, this is provided as a static method. Both the sink and the instrumentation settings are passed to instrumentedRunWith:
- Scala
-
import com.lightbend.cinnamon.akka.stream.CinnamonAttributes.SourceWithInstrumented implicit val materializer = ActorMaterializer() Source.single(0) .map(_ + 1) .instrumentedRunWith(Sink.ignore)(name = "my-stream") - Java
-
CinnamonAttributes.instrumentedRunWith( Source.single(0).map(x -> x + 1), Sink.ignore(), materializer, CinnamonAttributes.isInstrumented().withReportByName("my-stream"));
Instrumenting partial streams
Partial streams can be instrumented using the Instrumented attribute. This can be useful when only one part of the overall stream is of interest, such as when a Flow is being passed to another library such as Akka HTTP. To enable instrumentation for partial streams, first enable this feature in configuration:
cinnamon.akka.stream.partial = onThen attach the Instrumented attribute to a Source or Flow in the same way as enabling instrumentation for entire streams.
If the intention is to instrument the whole runnable graph, including the sinks, see the section about instrumented runWith on instrumenting all operators rather than only part of the stream.
For Scala, there is also an implicit extension method available to provide a more convenient way to enable instrumentation for partial streams. The method is similar to the instrumented extension method, but named instrumentedPartial.
For example, if the Flow handler approach in Akka HTTP is being used, then the Flow can be instrumented as a partial stream:
- Scala
-
import com.lightbend.cinnamon.akka.stream.CinnamonAttributes.FlowWithInstrumented val flow = Flow[HttpRequest] .map(request => HttpResponse(entity = "response")) .instrumentedPartial(name = "handler", traceable = true) Http().newServerAt(host, port).bindFlow(flow)
Stream and operator names
Cinnamon can create meaningful and unique names for streams and operators, to use when reporting metrics, events, or traces. Attributes attached to a stream or operator will be used, as well as the unique ids that the materializer associates with each stream or operator.
Stream names
The naming for streams depends on the report-by settings and either the named or instrumented attributes. Here are some examples:
Stream: not named and report-by-instance
If a stream is not named and is configured to report by instance, then the unique internal name created by the materializer is used.
The default pattern is flow-{id}.
- Scala
-
// example stream: not named and instrumented to report-by-instance Source.single(0).map(_ + 1) .instrumentedRunWith(Sink.ignore)(reportByInstance = true) - Java
-
// example stream: not named and instrumented to report-by-instance CinnamonAttributes.instrumentedRunWith( Source.single(0).map(x -> x + 1), Sink.ignore(), materializer, CinnamonAttributes.isInstrumented().withReportByInstance());
// expected naming for an unnamed stream with report-by-instance
name -> "flow-0"Stream: named and report-by-instance
If a stream is named and configured to report by instance, then the name is combined with the unique internal name created by the materializer.
The pattern is {name}-flow-{id}.
- Scala
-
// example stream: named and instrumented to report-by-instance Source.single(0) .map(_ + 1) .to(Sink.ignore) .named("my-stream") .instrumented(reportByInstance = true) .run() - Java
-
// example stream: named and instrumented to report-by-instance Source.single(0) .map(x -> x + 1) .to(Sink.ignore()) .named("my-stream") .addAttributes(CinnamonAttributes.instrumentedByInstance()) .run(materializer);
// expected naming for a named stream with report-by-instance
name -> "my-stream-flow-0"Stream: report-by-name
If a stream is named and configured to report by name, then just the given name is used.
The name can be provided by using the named attribute:
- Scala
-
// example stream: named and instrumented to report-by-name Source.single(0) .map(_ + 1) .to(Sink.ignore) .named("my-stream") .instrumented(reportByName = true) .run() - Java
-
// example stream: named and instrumented to report-by-name Source.single(0) .map(x -> x + 1) .to(Sink.ignore()) .named("my-stream") .addAttributes(CinnamonAttributes.instrumentedByName()) .run(materializer);
// expected naming for a named stream with report-by-name
name -> "my-stream"The name can also be provided directly with the instrumented attribute, which will automatically enable report by name:
- Scala
-
// example stream: named and instrumented to report-by-name Source.single(0).map(_ + 1) .instrumentedRunWith(Sink.ignore)(name = "my-stream") - Java
-
// example stream: named and instrumented to report-by-name CinnamonAttributes.instrumentedRunWith( Source.single(0).map(x -> x + 1), Sink.ignore(), materializer, CinnamonAttributes.isInstrumented().withReportByName("my-stream"));
// expected naming for a named stream with report-by-name
name -> "my-stream"Stream: report-by-name and report-by-instance
If a stream has multiple report-by settings, then metrics will be reported under multiple names. See examples above for names used for reporting by instance or name.
Operator names
Stream operator names are based on any name attributes attached to the operator, with a fallback to the class name of the operator if there are no attributed names. To ensure that operator names are unique, the ids assigned by the materializer for async islands and operator stages are always included in the name.
The pattern for operator names is {async-island-id}-{operator-stage-id}-{names}, where {names} are either all name attributes (ordered from least specific to most specific) or otherwise the (simple) class name for the operator.
Here are some examples:
Operators: no extra name attributes
If an instrumented stream has no extra name attributes, then the names will default to the built-in names provided by Akka Streams (either provided name attributes, or fallback to the simple class name).
- Scala
-
// example stream: with async island and without any extra name attributes Source(1 to 5) .map(_ + 1) .async .filter(_ % 2 == 0) .map(_ * 2) - Java
-
// example stream: with async island and without any extra name attributes Source.range(1, 5).map(x -> x + 1).async().filter(x -> x % 2 == 0).map(x -> x * 2);
// expected naming for operators without any extra name attributes
// source of iterable, highest id numbers
source -> "2-2-iterableSource"
// source of iterable is made up of two stages
sourceMapConcat -> "2-2-iterableSource"
// the first map is in a different async island from the second map
map1 -> "2-0-map"
// async boundary: output from first async island
outputBoundary -> "2-1-map-output-boundary"
// async boundary: input to second async island
inputBoundary -> "0-3-filter-input-boundary"
// the filter is in the second async island (first to be materialized)
filter -> "0-2-filter"
// the second map has the first ids
map2 -> "0-0-map"The stream materializer will traverse back through the graph from the sink, so downstream operators are assigned ids first. The ids are generally in reverse order.
Operators: with name attributes
If an instrumented stream has name attributes, then the operator names will include all attached and inherited name attributes. Note that attributes apply to the entire sub-graph when using the fluid DSLs. To isolate a name, create a named flow and use the via operator. See the Akka documentation on attributes for more information.
- Scala
-
// example stream: with extra name attributes // separate named flow val timesTwo = Flow[Int].map(_ * 2).named("times-two") Source(1 to 5) .map(_ + 1) .async.named("first") // applies to sub-graph above .via(Flow[Int].filter(_ % 2 == 0).named("even")) // inline named operator .via(timesTwo) - Java
-
// example stream: with extra name attributes // separate named flow Flow<Integer, Integer, NotUsed> timesTwo = Flow.of(Integer.class).map(x -> x * 2).named("times-two"); Source.range(1, 5) .map(x -> x + 1) .async() .named("first") // applies to sub-graph above .via(Flow.of(Integer.class).filter(x -> x % 2 == 0).named("even")) // inline named operator .via(timesTwo);
// expected naming for operators with name attributes
// source of iterable, highest id numbers, within the "first" part
source -> "2-2-first-iterableSource"
// source of iterable is made up of two stages, name includes "first"
sourceMapConcat -> "2-2-first-iterableSource"
// the first map is in the "first" async island, outer name is prepended
map1 -> "2-0-first-map"
// async boundary: output from first async island
outputBoundary -> "2-1-first-map-output-boundary"
// async boundary: input to second async island
inputBoundary -> "0-3-even-filter-input-boundary"
// the filter has an extra "even" name attached
filter -> "0-2-even-filter"
// the second map is from a separate named flow, with "times-two" prepended to default "map" name
timesTwo -> "0-0-times-two-map"The stream materializer will traverse back through the graph from the sink, so downstream operators are assigned ids first. The ids are generally in reverse order.
Substreams
Substreams will be instrumented using the settings of the super-stream (provided by configuration or attributes), and will be named based on the operator materializing the substream, with an additional -sub suffix:
- Scala
-
// example stream: with substreams and instrumented to report-by-name Source.single(0) .flatMapConcat(x => Source(x :: Nil)) .instrumentedRunWith(Sink.ignore)(name = "my-stream") - Java
-
// example stream: with substreams and instrumented to report-by-name CinnamonAttributes.instrumentedRunWith( Source.single(0).flatMapConcat(x -> Source.from(Arrays.asList(x))), Sink.ignore(), materializer, CinnamonAttributes.isInstrumented().withReportByName("my-stream"));
// expected naming for a substream, based on materializing operator
substream -> "my-stream-0-1-flattenMerge-sub"Telemetry for substreams can be disabled in the super-stream settings:
cinnamon.akka {
streams {
"example.streams.a.*" {
report-by = name
substreams = off
}
}
}Or using the instrumented attribute:
- Scala
-
Source.single(0) .flatMapConcat(x => Source(x :: Nil)) .instrumentedRunWith(Sink.ignore)(name = "my-stream", substreams = false) - Java
-
CinnamonAttributes.instrumentedRunWith( Source.single(0).flatMapConcat(x -> Source.from(Arrays.asList(x))), Sink.ignore(), materializer, CinnamonAttributes.isInstrumented().withReportByName("my-stream").withoutSubstreams());
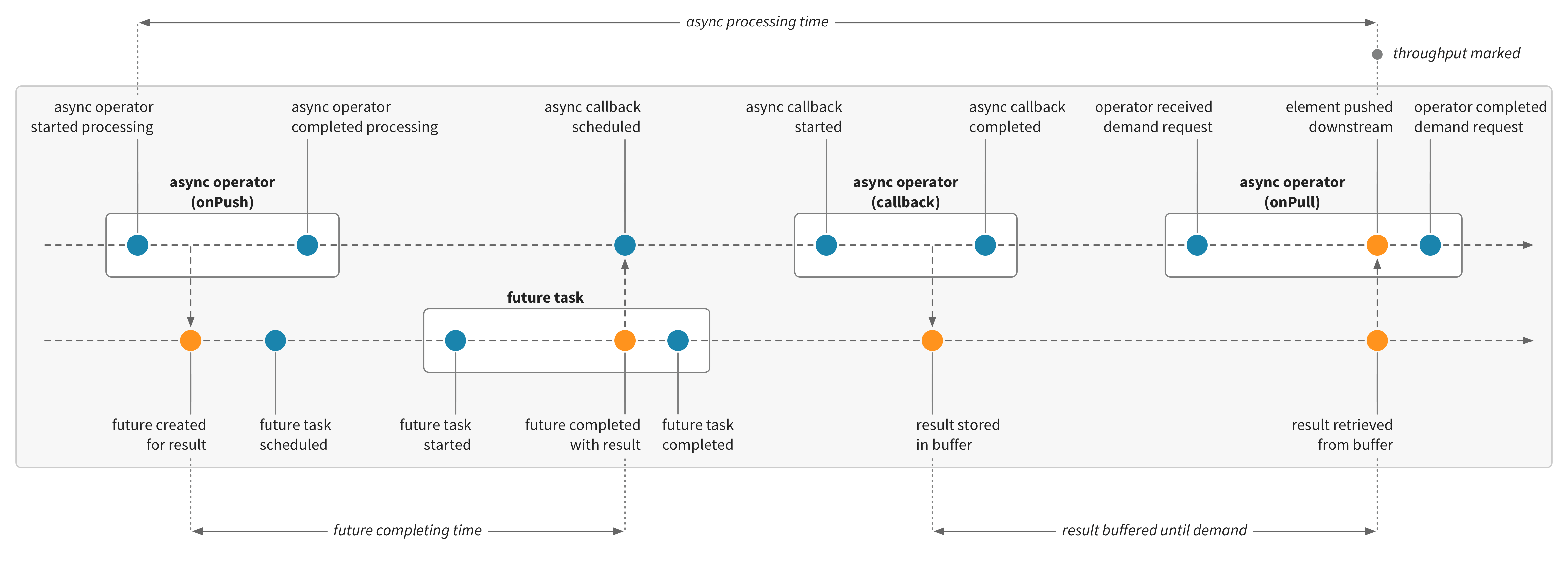
Asynchronous operators
Asynchronous stream operators, such as mapAsync or mapAsyncUnordered, process elements asynchronously—the initial element processing will register an asynchronous callback, which will re-enter the stream at a later time, when ready, to complete the processing and pass the result downstream. This means that the regular processing time for these operators will generally be very short, with the bulk of the time spent asynchronously elsewhere, such as in a Future or Actor. To handle this, Cinnamon will detect asynchronous operators and record the processing time for these specially, using a Stopwatch. The total time for asynchronous operators will be recorded, including any asynchronous processing or time in buffers, and until a result is pushed downstream.
The asynchronous processing time is disabled by default, and so is the Stopwatch that it is based on, and both of them need to be enabled:
cinnamon.stopwatch {
enabled = true
}
cinnamon.akka.stream.metrics {
async-processing-time = on
}The asynchronous processing time for a generic asynchronous operator is illustrated in this diagram:
Metric sampling
As streams can process elements quickly, measuring the processing time and throughput for every element flowing through a stream may be too costly. Akka Stream metrics can be configured with metric sampling to limit the instrumentation overhead. The default is to always sample every element, and the following sampling methods can be configured:
-
count — Sample every nth element flowing through each stream stage. The count-based sampler is efficient, but will strictly keep to sampling every nth element regardless of how frequently elements are processed.
-
time — Set a limit of sampled elements every time period. The time-based sampler will handle varying rates, by rate-limiting the samples in a time period, but has extra overhead from checking the current system time for each element.
-
adaptive — Dynamically adapt the sampling rate towards a target of once every time period. The adaptive sampler is like the count-based sampler, but the sampling of every nth element is dynamically adjusted based on the time between samples, using a moving average to adapt towards a target time period between samples.
The sampling method can be configured for all Akka Streams telemetry. For example, adaptive sampling with a target time period and limits can be configured:
- Example
-
cinnamon.akka.stream.metrics { sampling { method = adaptive adaptive { target = 200ms max-every = 1000 } } } - Reference
-
cinnamon.akka.stream.metrics { # Sampling settings for all Akka Stream metrics sampling { # Enabled sampling method can be: always | count | time | adaptive method = always # When enabled, sample every nth event count { # sample every nth event every = 100 } # When enabled, sample at most n events every time period time { # sample at most `limit` events every time period limit = 10 # time period to limit events within every = 1s } # When enabled, adapt sampling rate towards target of once every time period adaptive { # target of one sample every time period target = 100ms # weighting ratio of the latest value (for the moving average) weighting = 0.3 # minimum adapted sampling of every nth event min-every = 1 # maximum adapted sampling of every nth event max-every = 100 } } }NoteThese settings are defined in the
reference.conf. You only need to specify any of these settings when you want to override the defaults.
Suppressing potential call-site lookup warning
Available since Cinnamon 2.14.1
As mentioned in the selection by materialized code location section, call-site lookups are potentially expensive. As of version 2.14, Telemetry will emit a warning if your Akka stream configuration could result in potential call-site lookups. You can suppress this warning by setting the following configuration key to true:
- Reference
-
# Suppress warnings about potential call-site lookups? cinnamon.akka.stream.suppress-call-site-warnings = false
Extended telemetry
Extended telemetry can be enabled for recording end-to-end flow time, stream demand, latency, and per connection metrics. See Akka Stream extended telemetry.