







Akka Multi-DC Persistence
This chapter describes how Akka Persistence can be used across multiple data centers (DC), availability zones or regions.
This module has been replaced in open source Akka with Replicated Event Sourcing.
This module is currently marked as May Change in the sense of that the API might be changed based on feedback from initial usage. However, the module is ready for usage in production and we will not break serialization format of messages or stored data.
This feature is included in a subscription to Lightbend Platform, which includes other technology enhancements, monitoring and telemetry, and one-to-one support from the expert engineers behind Akka.
Akka Persistence basics
The reference documentation describes all details of Akka Persistence but here is a short summary in case you are not familiar with the concepts.
Akka persistence enables stateful actors to persist their internal state so that it can be recovered when an actor is started, restarted after a JVM crash or by a supervisor, or migrated in a cluster. The key concept behind Akka persistence is that only changes to an actor’s internal state are persisted but never its current state directly (except for optional snapshots). Such stateful actors are recovered by replaying stored changes to these actors from which they can rebuild internal state.
This design of capturing all changes as domain events, which are immutable facts of things that have happened, is known as event sourcing
Akka persistence supports event sourcing with the AbstractPersistentActor abstract class. An actor that extends this class uses the persist method to persist and handle events. The behavior of an AbstractPersistentActor is defined by implementing createReceiveRecover and createReceive. More details and examples can be found in the Akka documentation.
Another excellent article about “thinking in Events” is Events As First-Class Citizens by Randy Shoup. It is a short and recommended read if you’re starting developing Events based applications.
Motivation
There can be many reasons for using more than one data center, such as:
- Redundancy to tolerate failures in one location and still be operational.
- Serve requests from a location near the user to provide better responsiveness.
- Balance the load over many servers.
Akka Persistence is using event sourcing that is based on the single writer principle, which means that there can only be one active instance of a PersistentActor with a given persistenceId. Otherwise, multiple instances would store interleaving events based on different states, and when these events would later be replayed it would not be possible to reconstruct the correct state.
This restriction means that the single persistent actor can only live in one data center and would not be available during network partitions between the data centers. It is difficult to safely fail over the persistent actor from one data center to the other because:
- The underlying data store might not have replicated all data when network partition occured, meaning that some updates would be lost if starting the persistent actor in the other data center. It would be even more problematic if the data is later replicated when the network partition heals, resulting in similar problems as with multiple active persistent actors.
- To avoid above problem with lost or delayed data one could write all data with
QUORUMconsistency level across all data centers, but that would be very slow. - Detecting problem and failing over to another data center takes rather long time if it should be done with high confidence. Using ordinary Cluster Sharding and Split Brain Resolver would mean downing all nodes in a data center, which is likely not desired. Instead, one would typically like to wait until the network partition heals and accept that communication between the data centers is not possible in the meantime.
Approach
What if we could relax the single writer principle and allow persistent actors to be used in an active-active mode? The consistency boundary that we get from the ordinary persistent actor is nice and we would like to keep that within a data center, but network partitions across different data centers should not reduce availability. In other words, we would like one persistent actor instance in each data center and the persisted events should be replicated across the data centers with eventual consistency. Eventually, all events will be consumed by replicas in other data centers.
This new type of persistent replicated actor is called ReplicatedEntity.
When there is no network partitions and no concurrent writes the events stored by a ReplicatedEntity in one data center can be replicated and consumed by another (corresponding) instance in another data center without any concerns. Such replicated events can simply be applied to the local state.
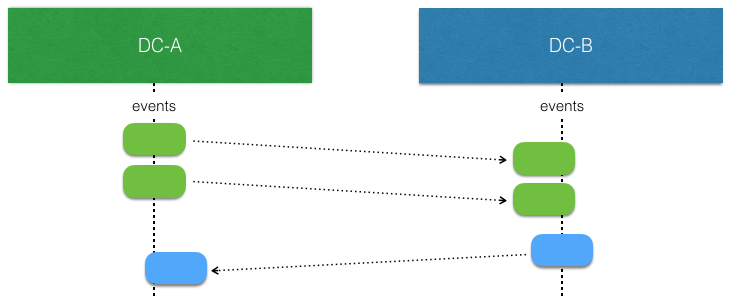
The interesting part begins when there are concurrent writes by ReplicatedEntity instances in different data centers. That is more likely to happen when there is a network partition, but it can also happen when there are no network issues. They simply write at the “same time” before the events from the other side have been replicated and consumed.
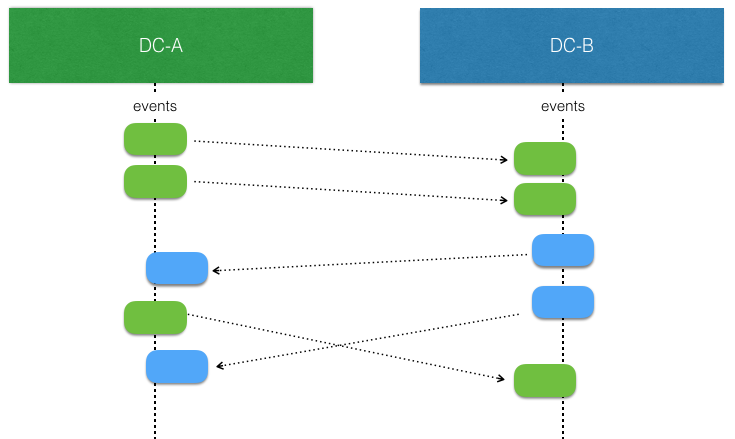
The ReplicatedEntity has support for resolving such conflicts but in the end the logic for applying events to the state of the entity must be aware of that such concurrent updates can occur and it must be modeled to handle such conflicts. This means that it should typically have the same characteristics as a Conflict Free Replicated Data Type (CRDT). With a CRDT there are by definition no conflicts and the events can just be applied. The library provides some general purpose CRDTs, but the logic of how to apply events can also be defined by an application specific function.
For example, sometimes it’s enough to use application specific timestamps to decide which update should win.
Strategies for resolving conflicts are described in detail later in this documentation.
To be able to support these things the ReplicatedEntity has a different API than the PersistentActor in Akka Persistence. The concepts should be familiar and migrating between the APIs should not be difficult. Events stored by a PersistentActor can be read by a ReplicatedEntity, meaning that it’s possible to migrate an existing application to use this feature. There are also migration paths back to PersistentActor if that would be needed. The API is similar to Lagom’s PersistentEntity, but it has the full power of an Actor if needed.
The solution is using existing infrastructure for persistent actors and Akka persistence plugins, meaning that much of it has been battle tested.
Cassandra is currently the only supported data store, but the solution is designed to allow for other future implementations.
The replication mechanism of the events is taking advantage of the multi data center support that exists in Cassandra, i.e. the data is replicated by Cassandra.
When to not use it
Akka Multi-DC Persistence is not suitable for:
- When all you need is a simple CRUD with last-writer wins, or optimistic locking semantics. Event sourcing and Multi-DC event sourcing is then overkill for the problem you are trying to solve and will increase complexity of the solution.
- When you need to ensure global constraints at all times. For example ensuring that an inventory balance is never negative even if updated from several data centers. Then you need a fully consistent system and Multi-DC Persistence is favoring availability.
- When read-modify-write transactions across several data centers are needed.
Dependency
To use the multi data center persistence feature a dependency on the akka-persistence-multi-dc artifact must be added.
- sbt
-
// Add Lightbend Platform to your build as documented at https://developer.lightbend.com/docs/lightbend-platform/introduction/getting-started/subscription-and-credentials.html "com.lightbend.akka" %% "akka-persistence-multi-dc" % "1.1.16" - Gradle
- Maven
Before you can access this library, you’ll need to configure the Lightbend repository and credentials in your build.
To use it together with Akka 2.6 you have to override the following Akka dependencies by defining them explicitly in your build and define the Akka version to one that you are using.
- sbt
libraryDependencies ++= Seq( "com.typesafe.akka" % "akka-persistence-query" % "2.6.4", "com.typesafe.akka" % "akka-persistence" % "2.6.4", "com.typesafe.akka" % "akka-cluster-sharding" % "2.6.4", "com.typesafe.akka" % "akka-cluster-tools" % "2.6.4" )- Maven
- Gradle
Getting started
A template project is available as Get Started download
for Java or for Scala. It contains instructions of how to run it in the README file.
ReplicatedEntity stub
This is what a ReplicatedEntity class looks like before filling in the implementation details:
- Scala
- Java
-
import akka.persistence.multidc.javadsl.CommandHandler; import akka.persistence.multidc.javadsl.EventHandler; import akka.persistence.multidc.javadsl.ReplicatedEntity; final class Post1 extends ReplicatedEntity<BlogCommands.BlogCommand, BlogEvents.BlogEvent, BlogState> { @Override public BlogState initialState() { return BlogState.EMPTY; } @Override public CommandHandler<BlogCommands.BlogCommand, BlogEvents.BlogEvent, BlogState> commandHandler() { throw new RuntimeException("Not implemented yet"); } @Override public EventHandler<BlogEvents.BlogEvent, BlogState> eventHandler() { throw new RuntimeException("Not implemented yet"); } }
Command- the super class/interface of the commandsEvent- the super class/interface of the eventsState- the class of the state
initialState is an abstract method that your concrete subclass must implement to define the State when the entity is first created.
commandHandler is an abstract method that your concrete subclass must implement to define the actions of the entity. CommandHandler defines command handlers and optional functions for other signals, e.g. Termination messages if watch is used.
eventHandler is the event handler that updates the current state when an event has been persisted.
Command Handlers
The commands for this example:
- Scala
- Java
-
final static class AddPost implements BlogCommand { final String postId; final BlogState.PostContent content; public AddPost(String postId, BlogState.PostContent content) { this.postId = postId; this.content = content; } public String getPostId() { return postId; } } final static class AddPostDone { final String postId; AddPostDone(String postId) { this.postId = postId; } public String getPostId() { return postId; } } final static class GetPost implements BlogCommand { final String postId; public GetPost(String postId) { this.postId = postId; } public String getPostId() { return postId; } } final static class ChangeBody implements BlogCommand { final String postId; final BlogState.PostContent newContent; public ChangeBody(String postId, BlogState.PostContent newContent) { this.postId = postId; this.newContent = newContent; } public String getPostId() { return postId; } } final static class Publish implements BlogCommand { final String postId; public Publish(String postId) { this.postId = postId; } public String getPostId() { return postId; } }
The function that processes incoming commands is defined by the mandatory commandHandler:
- Scala
- Java
-
// The command handler is invoked for incoming messages (commands). // A command handler must "return" the events to be persisted (if any). final CommandHandler<BlogCommand, BlogEvent, BlogState> initial = commandHandlerBuilder(BlogCommand.class) .matchCommand(AddPost.class, (ctx, state, addPost) -> { BlogEvents.PostAdded evt = new PostAdded( addPost.postId, addPost.content, state.contentTimestamp.increase(currentTimeMillis(), getSelfDc()) ); return Effect().persist(evt).andThen((newState) -> // After persist is done additional side effects can be performed ctx.getSender().tell(new BlogCommands.AddPostDone(addPost.postId), getSelf())); }).matchAny((cmd, state, ctx) -> Effect().unhandled());
The command handler can be built from functions with 3 parameters for the Command, the CommandContext and current State.
A command handler returns an Effect directive that defines what event or events, if any, to persist. Use the persist, none or unhandled methods of Effect() to create the Effect directives:
Effect().persistcan be used to persist one or many events. This method is overloaded and offers few variants. You can pass oneEvent, aList<Event>or anOptional<Event>. Events are atomically persisted, i.e. all events are stored or none of them are stored if there is an errorEffect().noneno events are to be persisted, for example a read-only commandEffect().unhandledthe command is unhandled (not supported) in current state
External side effects can be performed after successful persist with the andThen function. In the above example a reply is sent to the sender. Note that current state after applying the event is passed as parameter to the andThen function.
The command can be validated before persisting state changes. Note that the updated state is passed as a parameter to the command handler function:
- Scala
- Java
-
commandHandlerBuilder(BlogCommand.class) .matchCommand(AddPost.class, // predicate to catch invalid requests (addPost) -> addPost.content.title == null || addPost.content.title.equals(""), (ctx, blogState, addPost) -> { ctx.getSender().tell(new Status.Failure(new IllegalArgumentException("Title must be defined")), getSelf()); return Effect().none(); }) .matchCommand(AddPost.class, (ctx, blogState, addPost) -> { PostAdded evt = new PostAdded( addPost.postId, addPost.content, blogState.contentTimestamp.increase(currentTimeMillis(), getSelfDc())); return Effect().persist(evt).andThen((newState) -> // After persist is done additional side effects can be performed ctx.getSender().tell(new AddPostDone(addPost.postId), getSelf())); }).matchAny((other, state, ctx) -> Effect().unhandled());
A ReplicatedEntity may also process commands that do not change application state, such as query commands or commands that are not valid in the entity’s current state (such as a bid placed after the auction closed). Instead of using Effect().persist you can simply return Effect().none() for such read-only commands. Replies are sent as ordinary actor messages to the sender of the context that is passed to the command handler function, or to any other ActorRef in the commands or state.
- Scala
- Java
-
) .matchCommand(GetPost.class, (ctx, state, getPost) -> { ctx.getSender().tell(state.content.get(), getSelf()); return Effect().none(); })
The commands must be immutable to avoid concurrency issues that may occur from changing a command instance that has been sent.
You need to create a serializer for the commands so that they can be sent as remote messages in the Akka cluster. We recommend against using Java serialization.
Event Handlers
The events for this example:
- Scala
- Java
-
import akka.persistence.multidc.crdt.LwwTime; interface BlogEvent {} final static class PostAdded implements BlogEvent { final String postId; final BlogState.PostContent content; final LwwTime timestamp; public PostAdded(String postId, BlogState.PostContent content, LwwTime timestamp) { this.postId = postId; this.content = content; this.timestamp = timestamp; } } final static class BodyChanged implements BlogEvent { final String postId; final BlogState.PostContent content; final LwwTime timestamp; public BodyChanged(String postId, BlogState.PostContent content, LwwTime timestamp) { this.postId = postId; this.content = content; this.timestamp = timestamp; } } final static class Published implements BlogEvent { final String postId; public Published(String postId) { this.postId = postId; } }
When an event has been persisted successfully the current state is updated by applying the event to the current state. The method for updating the state is eventHandler and it must be implemented by the concrete ReplicatedEntity class.
- Scala
- Java
-
// the returned event handler is used both when persisting new events, replaying // events, and consuming replicated events. @Override public EventHandler<BlogEvent, BlogState> eventHandler() { return eventHandlerBuilder(BlogEvent.class) .matchEvent(PostAdded.class, (state, postAdded) -> { if (postAdded.timestamp.isAfter(state.contentTimestamp)) { return state.withContent(postAdded.content, postAdded.timestamp); } else { return state; } }) .matchEvent(BodyChanged.class, (state, bodyChanged) -> { if (bodyChanged.timestamp.isAfter(state.contentTimestamp)) { return state.withContent(bodyChanged.content, bodyChanged.timestamp); } else { return state; } }) .matchEvent(Published.class, (state, publish) -> state.publish()) .matchAny((state, otherEvent) -> state); }
The event handler returns the new state. The state must be immutable, so you return a new instance of the state. Current state is passed as a parameter to the event handler function. The same event handler is also used when the entity is started up to recover its state from the stored events, and for consuming replicated events and updating the state from those.
In this example we use a timestamp to resolve conflicting concurrent updates. The events such as BodyChanged contain a LwwTime that holds current time when the event was persisted and an identifier of the data center that persisted it. Greatest timestamp wins. The data center identifier is used if two timestamps are equal, and then the one from the data center sorted first in alphanumeric order wins. Such conflict resolution is often called last writer wins and is described in more detail later
The events must be immutable to avoid concurrency issues that may occur from changing an event instance that is about to be persisted.
You need to create a serializer for the events, which are stored. We recommend against using Java serialization. When picking serialization solution for the events you should also consider that it must be possible read old events when the application has evolved. Strategies for that can be found in the Akka documentation.
State
The state for this example:
- Scala
- Java
-
import akka.persistence.multidc.crdt.LwwTime; import java.util.Optional; public class BlogState { final static class PostContent { final String title; final String body; public PostContent(String title, String body) { this.title = title; this.body = body; } } final static class PostSummary { final String postId; final String title; public PostSummary(String postId, String title) { this.postId = postId; this.title = title; } } public final static BlogState EMPTY = new BlogState( Optional.empty(), new LwwTime(Long.MIN_VALUE, ""), false); final Optional<PostContent> content; final LwwTime contentTimestamp; final boolean published; public BlogState(Optional<PostContent> content, LwwTime contentTimestamp, boolean published) { this.content = content; this.contentTimestamp = contentTimestamp; this.published = published; } BlogState withContent(PostContent newContent, LwwTime timestamp) { return new BlogState(Optional.of(newContent),timestamp, this.published); } BlogState publish() { if (published) { return this; } else { return new BlogState(content, contentTimestamp, true); } } boolean isEmpty() { return !content.isPresent(); } }
The state must be immutable to avoid concurrency issues that may occur from changing a state instance that is about to be saved as snapshot.
You need to create a serializer for the state, because it is stored as snapshot. We recommend against using Java serialization. When picking serialization solution for the snapshot you should also consider that it might be necessary to read old snapshots when the application has evolved. Strategies for that can be found in the Akka documentation. It is not mandatory to be able to read old snapshots. If it fails it will instead replay more old events, which might have a performance cost.
Changing Behavior
For simple entities you can use the same set of command handlers independent of what state the entity is in. The actions can then be defined like this:
- Scala
- Java
-
public CommandHandler<BlogCommand, BlogEvent, BlogState> commandHandler() { return commandHandlerBuilder(BlogCommand.class) .matchCommand(AddPost.class, (ctx, state, cmd) -> { final PostAdded evt = new PostAdded(cmd.postId, cmd.content, state.contentTimestamp.increase(currentTimeMillis(), getSelfDc())); return Effect().persist(evt).andThen((state2) -> // After persist is done additional side effects can be performed ctx.getSender().tell(new AddPostDone(cmd.postId), getSelf()) ); }) .matchCommand(ChangeBody.class, (ctx, state, cmd) -> { BodyChanged evt = new BodyChanged(cmd.getPostId(), cmd.newContent, state.contentTimestamp.increase(currentTimeMillis(), getSelfDc())); return Effect().persist(evt).andThen((newState) -> ctx.getSender().tell(Done.getInstance(), getSelf())); }) .matchCommand(Publish.class, (ctx, state, cmd) -> Effect().persist(new Published(cmd.postId)) .andThen((newState) -> ctx.getSender().tell(Done.getInstance(), getSelf())) ) .matchCommand(GetPost.class, (ctx, state, cmd) -> { ctx.getSender().tell(state.content.get(), getSelf()); return Effect().none(); }) .matchAny((ctx, state, cmd) -> Effect().unhandled()); }
When the state changes it can also change the behavior of the entity in the sense that new functions for processing commands may be defined. This is useful when implementing finite state machine (FSM) like entities. The CommandHandler can be selected based on current state by using the byStateCommandHandlerBuilder. It defines a mapping from current State to CommandHandler, which is called for each incoming command to select which CommandHandler to use to process the command.
This is how to define different behavior for different State:
- Scala
- Java
-
return byStateCommandHandlerBuilder(BlogState.class) .matchState(BlogState::isEmpty, initial) .matchAny(postAdded);
- Scala
- Java
-
// The command handler is invoked for incoming messages (commands). // A command handler must "return" the events to be persisted (if any). final CommandHandler<BlogCommand, BlogEvent, BlogState> initial = commandHandlerBuilder(BlogCommand.class) .matchCommand(AddPost.class, (ctx, state, addPost) -> { BlogEvents.PostAdded evt = new PostAdded( addPost.postId, addPost.content, state.contentTimestamp.increase(currentTimeMillis(), getSelfDc()) ); return Effect().persist(evt).andThen((newState) -> // After persist is done additional side effects can be performed ctx.getSender().tell(new BlogCommands.AddPostDone(addPost.postId), getSelf())); }).matchAny((cmd, state, ctx) -> Effect().unhandled());
- Scala
- Java
-
final CommandHandler<BlogCommand, BlogEvent, BlogState> postAdded = commandHandlerBuilder(BlogCommand.class) .matchCommand(ChangeBody.class, (ctx, state, changeBody) -> { BodyChanged evt = new BodyChanged(changeBody.postId, changeBody.newContent, state.contentTimestamp.increase(currentTimeMillis(), getSelfDc())); return Effect().persist(evt).andThen((newState) -> ctx.getSender().tell(Done.getInstance(), getSelf()) ); }) .matchCommand(Publish.class, (ctx, state, publish) -> Effect().persist(new Published(publish.postId)).andThen((newState) -> ctx.getSender().tell(Done.getInstance(), getSelf())) ) .matchCommand(GetPost.class, (ctx, state, getPost) -> { ctx.getSender().tell(state.content.get(), getSelf()); return Effect().none(); }) .matchAny((ctx, state, other) -> Effect().unhandled());
The event handler is always the same independent of state. The main reason for not making the event handler dynamic like the CommandHandler is that replicated events may be delayed and all events should be handled independent of what the current state is.
Minimum configuration
There are a few configuration properties that are needed to enable this feature. Here are required configuration properties for running with a single Akka node and a local Cassandra server:
akka.actor {
provider = cluster
}
akka.remote {
netty.tcp {
hostname = "127.0.0.1"
port = 2552
}
}
akka.cluster {
seed-nodes = ["akka.tcp://ClusterSystem@127.0.0.1:2552"]
multi-data-center.self-data-center = DC-A
}
akka.persistence {
snapshot-store.plugin = "cassandra-snapshot-store"
multi-data-center {
all-data-centers = ["DC-A", "DC-B"]
}
}
Running the entity
The ReplicatedEntity is not an Actor, but it is run by an actor and have the same message processing semantics as an actor, i.e. each command/message is processed sequentially, one at a time, for a specific entity instance. It also has the same semantics when persisting events as PersistentActor, i.e. incoming commands/messages are stashed until the persist is completed.
To start the entity you need to create the Props of the actor:
- Scala
- Java
-
import akka.cluster.Cluster; import akka.persistence.multidc.PersistenceMultiDcSettings; import akka.persistence.multidc.SpeculativeReplicatedEvent; import akka.persistence.multidc.javadsl.ReplicatedEntity; import java.util.Optional; Props props = ReplicatedEntity.props( BlogCommands.BlogCommand.class, "blog", "post-1", Post2::new, settings);
The parameters to the props are:
persistenceIdPrefix- Prefix for thepersistenceId. Empty string is a valid prefix if theentityIditself is globally unique. Note that this can’t be changed, since it is part of the storage key (persistenceId).entityId- The identifier of the entity.entityFactory- Factory for creating a new instance of the entity. It has to be a factory so that a new instance is created in case the actor is restarted.settings- Configuration settings.
The persistenceId is the concatenation of persistenceIdPrefix, entityId and the data center identifier, separated with |. This must be a globally unique identifier.
Then you can start the actor with actorOf:
- Scala
- Java
-
import akka.actor.ActorRef; import akka.actor.ActorSystem; import akka.actor.Props; ActorRef ref = system.actorOf(props); ref.tell( new BlogCommands.AddPost( "post-1", new BlogState.PostContent("First post", "...")), sender);
and send commands as messages via the ActorRef.
ReplicatedEntity is typically used together with Cluster Sharding and then the Props is obtained with ReplicatedEntity.clusterShardingProps. Then the Props is registered with the ClusterSharding extension and commands sent via the ActorRef of the ShardRegion like this:
- Scala
- Java
-
import akka.cluster.sharding.ClusterSharding; import akka.cluster.sharding.ClusterShardingSettings; import akka.cluster.sharding.ShardRegion; ShardRegion.MessageExtractor messageExtractor = new ShardRegion.MessageExtractor() { @Override public String entityId(Object message) { if (message instanceof BlogCommands.BlogCommand) { return ((BlogCommands.BlogCommand) message).getPostId(); } else { return null; } } @Override public Object entityMessage(Object message) { return message; } private String shardId(String entityId) { int maxNumberOfShards = 1000; return Integer.toString(Math.abs(entityId.hashCode()) % maxNumberOfShards); } @Override public String shardId(Object message) { if (message instanceof BlogCommands.BlogCommand) { return shardId(((BlogCommands.BlogCommand) message).getPostId()); } else if (message instanceof ShardRegion.StartEntity) { return shardId(((ShardRegion.StartEntity) message).entityId()); } else { return null; } } }; Props props = ReplicatedEntity.clusterShardingProps( BlogCommands.BlogCommand.class, "blog", Post2::new, persistenceMultiDcSettings); ClusterShardingSettings settings = ClusterShardingSettings.create(system); ActorRef region = ClusterSharding.get(system).start( "blog", props, settings, messageExtractor); region.tell( new BlogCommands.AddPost( "post-1", new BlogState.PostContent("First post", "...")), sender);
Resolving conflicting updates
Conflict Free Replicated Data Types
Writing code to resolve conflicts can be complicated to get right. One well-understood technique to create eventually-consistent systems is to model your state as a Conflict Free Replicated Data Type, a CRDT. There are two types of CRDTs; operation-based and state-based. For the ReplicatedEntity the operation-based is a good fit, since the events represent the operations. Note that this is distinct from the CRDT’s implemented in Akka Distributed Data, which are state-based rather than operation-based.
The rule for operation-based CRDT’s is that the operations must be commutative — in other words, applying the same events (which represent the operations) in any order should always produce the same final state. You may assume each event is applied only once, with causal delivery order.
The library provides some general purpose CRDT implementations that you can use as the state or part of the state in the entity. However, you are not limited to those types. You can write custom CRDT implementations and more importantly you can implement the application specific eventHandler function with the semantics of a CRDT in mind.
A simple example would be a movies watch list that is represented by the general purpose ORSet CRDT. ORSet is short for Observed Remove Set. Elements can be added and removed any number of times. Concurrent add wins over remove. It is an operation based CRDT where the delta of an operation (add/remove) can be represented as an event.
Such movies watch list example:
- Scala
- Java
-
import akka.actor.Props; import akka.persistence.multidc.PersistenceMultiDcSettings; import akka.persistence.multidc.crdt.ORSet; import akka.persistence.multidc.javadsl.CommandHandler; import akka.persistence.multidc.javadsl.EventHandler; import akka.persistence.multidc.javadsl.ReplicatedEntity;public class MovieWatchList extends ReplicatedEntity<MovieWatchList.Command, ORSet.DeltaOp, ORSet<String>> { interface Command { } public static class AddMovie implements Command { public final String movieId; public AddMovie(String movieId) { this.movieId = movieId; } } public static class RemoveMovie implements Command { public final String movieId; public RemoveMovie(String movieId) { this.movieId = movieId; } } public static class GetMovieList implements Command { static final GetMovieList INSTANCE = new GetMovieList(); private GetMovieList() { } } public static class MovieList { public final Set<String> movieIds; public MovieList(Set<String> movieIds) { this.movieIds = Collections.unmodifiableSet(movieIds); } } public static Props props(PersistenceMultiDcSettings settings) { return ReplicatedEntity.clusterShardingProps(Command.class,"movies", () -> new MovieWatchList(), settings); } @Override public ORSet<String> initialState() { return ORSet.empty(getSelfDc()); } @Override public CommandHandler<Command, ORSet.DeltaOp, ORSet<String>> commandHandler() { return commandHandlerBuilder(Command.class) .matchCommand(AddMovie.class, (ctx, state, cmd) -> { return Effect().persist(state.add(cmd.movieId)); }) .matchExactCommand(GetMovieList.INSTANCE, (ctx, state, cmd) -> { ctx.getSender().tell(new MovieList(state.getElements()), ctx.getSelf()); return Effect().none(); }) .build(); } @Override public EventHandler<ORSet.DeltaOp, ORSet<String>> eventHandler() { return eventHandlerBuilder(ORSet.DeltaOp.class) .matchAny((state, evt) -> { return state.applyOperation(evt); }); } }
The Auction Example is a more comprehensive example that illustrates how application-specific rules can be used to implement an entity with CRDT semantics.
Last writer wins
Sometimes it is enough to use timestamps to decide which update should win. Such approach relies on synchronized clocks, and clocks of different machines will always be slightly out of sync. Timestamps should therefore only be used used when the choice of value is not important for concurrent updates occurring within the clock skew.
In general, last writer wins means that the event is used if the timestamp of the event is later (higher) than the timestamp of previous local update, otherwise the event is discarded. There is no built-in support for last writer wins, because it must often be combined with more application specific aspects.
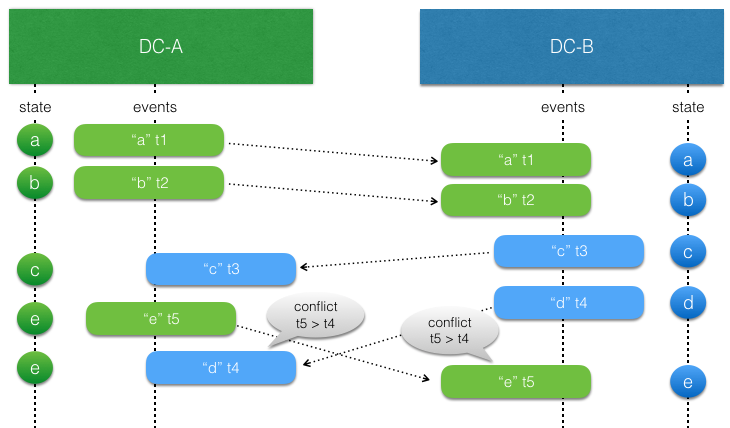
There is a small utility class LwwTime that can be useful for implementing last writer wins semantics. It contains a timestamp representing current time when the event was persisted and an identifier of the data center that persisted it. When comparing two LwwTime the greatest timestamp wins. The data center identifier is used if the two timestamps are equal, and then the one from the data center sorted first in alphanumeric order wins.
In this example the isAfter method in LwwTime is used to compare such timestamps:
- Scala
- Java
-
// the returned event handler is used both when persisting new events, replaying // events, and consuming replicated events. @Override public EventHandler<BlogEvent, BlogState> eventHandler() { return eventHandlerBuilder(BlogEvent.class) .matchEvent(PostAdded.class, (state, postAdded) -> { if (postAdded.timestamp.isAfter(state.contentTimestamp)) { return state.withContent(postAdded.content, postAdded.timestamp); } else { return state; } }) .matchEvent(BodyChanged.class, (state, bodyChanged) -> { if (bodyChanged.timestamp.isAfter(state.contentTimestamp)) { return state.withContent(bodyChanged.content, bodyChanged.timestamp); } else { return state; } }) .matchEvent(Published.class, (state, publish) -> state.publish()) .matchAny((state, otherEvent) -> state); }
When creating the LwwTime it is good to have a monotonically increasing timestamp, and for that the increase method in LwwTime can be used:
- Scala
- Java
-
// The command handler is invoked for incoming messages (commands). // A command handler must "return" the events to be persisted (if any). final CommandHandler<BlogCommand, BlogEvent, BlogState> initial = commandHandlerBuilder(BlogCommand.class) .matchCommand(AddPost.class, (ctx, state, addPost) -> { BlogEvents.PostAdded evt = new PostAdded( addPost.postId, addPost.content, state.contentTimestamp.increase(currentTimeMillis(), getSelfDc()) ); return Effect().persist(evt).andThen((newState) -> // After persist is done additional side effects can be performed ctx.getSender().tell(new BlogCommands.AddPostDone(addPost.postId), getSelf())); }).matchAny((cmd, state, ctx) -> Effect().unhandled());
The nature of last writer wins means that if you only have one timestamp for the state the events must represent an update of the full state, otherwise there is a risk that the state in different data centers will be different and not eventually converge to the same state.
An example of that would be an entity representing a blog post and the fields author and title could be updated separately with events new AuthorChanged(newAuthor) and new TitleChanged(newTitle).
Let’s say the blog post is created and the initial state of title=Akka, author=unknown is in sync in both data centers DC-A and DC-B.
In DC-A author is changed to “Bob” at time 100. Before that event has been replicated over to DC-B the title is updated to “Akka News” at time 101 in DC-B. When the events have been replicated the result will be:
DC-A: The title update is later so the event is used and new state is title=Akka News, author=Bob
DC-B: The author update is earlier so the event is discarded and state is title=Akka News, author=unknown
The problem here is that the partial update of the state is not applied on both sides, so the states have diverged and will not become the same.
To solve this with last writer wins the events must carry the full state, such as new AuthorChanged(newContent) and new TitleChanged(newContent). Then the result would eventually be title=Akka News, author=unknown on both sides. The author update is lost but that is because the changes were performed concurrently. More important is that the state is eventually consistent.
Including the full state in each event is often not desired. An event typically represent a change, a delta. Then one can use several timestamps, one for each set of fields that can be updated together. In the above example one could use one timestamp for the title and another for the author. Then the events could represent changes to parts of the full state, such as new AuthorChanged(newAuthor) and new TitleChanged(newTitle).
The above Getting started example is using last writer wins.
Additional information about the events
The eventHandler is used both when persisting new events, replaying events, and consuming replicated events. Sometimes it can be good know the difference of these cases and have some additional meta data about the event. For that purpose you may optionally override selfEventHandler and replicatedEventHandler. By default these delegate to eventHandler.
The additional information for both these methods:
timestamp- time when the event was persisted as returned byReplicatedEntity.currentTimeMillis, which is typically in epoch milliseconds, i.e. milliseconds since midnight, January 1, 1970 UTCsequenceNr- the sequence number of the eventrecoveryRunning-truewhen the event is applied from replay when recovering the state at startup,falseif it was persisted now
Different data centers may have different sequence numbers for their own event log.
For applyReplicatedEvent there are also:
originDcthe event was persisted by this data centerconcurrentsee Detecting concurrent updates
Detecting concurrent updates
There is a feature to enable tracking of causality between events to detect concurrent updates. The ReplicatedEventContext that is passed as parameter to applyReplicatedEvent has the concurrent flag to indicate if an event was persisted with a causal relation to previous event here (concurrent=false), or if an update occurred in both data centers before the events had been replicated to the other side (concurrent=true).
Here is an example of registry that accept updates when they are in causal order but for concurrent updates it prefers one data center:
- Scala
- Java
-
@Override public Registry replicatedEventHandler(ReplicatedEventContext ctx, Registry state, BiasedRegistryEvents.BiasedRegistryEvent event) { // lowest DC wins if concurrent update if (ctx.concurrent() && (selfDc().compareTo(ctx.originDc()) < 0)) { return state; } else { return internalApplyEvent(state, event); } } @Override public EventHandler<BiasedRegistryEvents.BiasedRegistryEvent, Registry> eventHandler() { return eventHandlerBuilder(BiasedRegistryEvents.BiasedRegistryEvent.class) .matchEvent(BiasedRegistryEvents.Changed.class, (state, changed) -> { return new Registry(changed.item); }) .build(); }
Detecting concurrent updates are done by storing a version vector with each event and comparing that with a local version vector when the event is delivered. When using pure CRDTs it is typically not needed to care about if an event is concurrent or not, since CRDT operations must be commutative.
Side effects
The general recommendation for external side effects is to perform them using the andThen callbacks. The andThen callbacks are called after the events are persisted. In case no events are emitted, e.g. when passing an empty List<Event>or using Effect().none(), the callbacks are immediately called.
Side effects from the event handler are generally discouraged, because the event handlers are also used during replay and when consuming replicated events and that would result in undesired re-execution of the side effects.
recoveryCompleted can be a good place to based on current state after recovery retry the side effects that were intended to be performed but have not been confirmed yet. You would typically persist one event for the intention to perform the side effect before doing it, and then store an acknowledgment event when it has been confirmed by the destination that is was performed.
One can try best effort to only perform side effects once but to achieve effectively once-and-only-once the destination must be able to de-duplicate retried requests (or the side effect is idempotent in other ways).
Coordination between different data centers for deciding where a side effect should be performed is not provided by the ReplicatedEntity. You have to use another tool for such consensus decisions, e.g. ZooKeeper. You could also simply decide that such side effects should only be performed by one data center, but you would still have to handle duplicate attempts.
Triggers
For some use cases you may need to trigger side effects after consuming replicated events. For example when an auction has been closed in all data centers and all bids have been replicated. Another example could be workflow process that requires confirmation that other data centers have received certain facts (events) before proceeding with next step in the process.
To be able to perform side effects, and also persisting new events, in reaction to consuming events from own or other data centers you can override the method eventTrigger in the ReplicatedEntity. It is called for all events, but it is not called during recovery. Side effects after recovery should be done in recoveryCompleted based on the state.
Here is an example of a workflow process that is using triggers to continue the process when a step has been approved by the authority of all data centers.
- Scala
- Java
-
/** * Example of a workflow process that is using triggers to continue the process * when a step has been approved by the authority of all DCs. The process is * denied if any step is denied by any DC. */ public static class Process extends ReplicatedEntity<Process.Command, Process.Event, Process.State> { interface Command { } public static class Run implements Command { static final Run INSTANCE = new Run(); private Run() { } } public static class GetState implements Command { static final GetState INSTANCE = new GetState(); private GetState() { } } interface Event { } public static class StepStarted implements Event { final int stepNr; public StepStarted(int stepNr) { this.stepNr = stepNr; } } public static class StepApproved implements Event { final int stepNr; final String byDc; public StepApproved(int stepNr, String byDc) { this.stepNr = stepNr; this.byDc = byDc; } } public static class StepDenied implements Event { final int stepNr; final String byDc; public StepDenied(int stepNr, String byDc) { this.stepNr = stepNr; this.byDc = byDc; } } public static class State { final int currentStep; final Set<String> stepApprovedByDc; final boolean denied; final Set<String> allDcs; public State(int currentStep, Set<String> stepApprovedByDc, boolean denied, Set<String> allDcs) { this.currentStep = currentStep; this.stepApprovedByDc = Collections.unmodifiableSet(stepApprovedByDc); this.denied = denied; this.allDcs = Collections.unmodifiableSet(allDcs); } public State addStepApprovedByDc(String dc) { Set<String> newStepApprovedByDc = new HashSet<>(stepApprovedByDc); newStepApprovedByDc.add(dc); return new State(currentStep, newStepApprovedByDc, denied, allDcs); } public State withDenied() { return new State(currentStep, stepApprovedByDc, true, allDcs); } public boolean isStarted() { return currentStep > 0; } public boolean isApproved(int stepNr) { return !denied && stepApprovedByDc.equals(allDcs); } public boolean isCurrentStepApproved() { return isApproved(currentStep); } } // Messages to the Authority actor public static class RequestApproval { final int stepNr; public RequestApproval(int stepNr) { this.stepNr = stepNr; } } public static class Authorized implements Command { final int stepNr; public Authorized(int stepNr) { this.stepNr = stepNr; } } public static class Denied implements Command { final int stepNr; public Denied(int stepNr) { this.stepNr = stepNr; } } private static class ResendTick implements Command { static final ResendTick INSTANCE = new ResendTick(); private ResendTick() { } } private static final FiniteDuration resendInterval = Duration.create(1, TimeUnit.SECONDS); private final ActorRef authority; private final int maxSteps; public Process(ActorRef authority, int maxSteps) { this.authority = authority; this.maxSteps = maxSteps; } @Override public State initialState() { return new State(0, Collections.emptySet(), false, Collections.emptySet()); } @Override public CommandHandler<Command, Event, State> commandHandler() { return commandHandlerBuilder(Command.class) .matchExactCommand(Run.INSTANCE, (ctx, state, cmd) -> { if (state.currentStep == maxSteps) { return Effect().none(); // all steps completed } else if (state.isCurrentStepApproved() || !state.isStarted()) { return Effect().persist(new StepStarted(state.currentStep + 1)); } else if (state.isStarted() && !state.stepApprovedByDc.contains(getSelfDc())) { // resend after crash/recovery authority.tell(new RequestApproval(state.currentStep), ctx.getSelf()); ctx.getTimers().startPeriodicTimer(ResendTick.INSTANCE, ResendTick.INSTANCE, resendInterval); return Effect().none(); } else { return Effect().none(); // in progress, waiting for approvals } }) .matchCommand(Authorized.class, (ctx, state, cmd) -> { if (state.currentStep == cmd.stepNr && !state.stepApprovedByDc.contains(getSelfDc())) { ctx.getTimers().cancel(ResendTick.INSTANCE); return Effect().persist(new StepApproved(cmd.stepNr, getSelfDc())); } else return Effect().none(); // duplicate from resending to authority }) .matchCommand(Denied.class, (ctx, state, cmd) -> { ctx.getTimers().cancel(ResendTick.INSTANCE); return Effect().persist(new StepDenied(cmd.stepNr, getSelfDc())); }) .matchCommand(GetState.class, (ctx, state, cmd) -> { ctx.getSender().tell(state, ctx.getSelf()); return Effect().none(); }) .onTimer(ResendTick.class, (ctx, state, msg) -> { // resend to authority, at-least-once log().info("resending RequestApproval for step {}", state.currentStep); authority.tell(new RequestApproval(state.currentStep), ctx.getSelf()); return Effect().none(); }) .build(); } @Override public Effect<Event, State> recoveryCompleted(ActorContext ctx, State state) { if (getSelfDc().equals("DC-A")) ctx.getSelf().tell(Run.INSTANCE, ActorRef.noSender()); return Effect().none(); } @Override public EventHandler<Event, State> eventHandler() { return eventHandlerBuilder(Event.class) .matchEvent(StepStarted.class, (state, evt) -> { return new State(evt.stepNr, Collections.emptySet(), false, getAllDcs()); }) .matchEvent(StepApproved.class, (state, evt) -> { return state.addStepApprovedByDc(evt.byDc); }) .matchEvent(StepDenied.class, (state, evt) -> { return state.withDenied(); }) .build(); } @Override public Effect<Event, State> eventTrigger(EventTriggerContext ctx, State state, Event event) { if (event instanceof StepStarted) { StepStarted stepStarted = (StepStarted) event; authority.tell(new RequestApproval(stepStarted.stepNr), ctx.actorContext().getSelf()); ctx.actorContext().getTimers().startPeriodicTimer(ResendTick.INSTANCE, ResendTick.INSTANCE, resendInterval); return Effect().none(); } else if (event instanceof StepApproved) { StepApproved stepApproved = (StepApproved) event; if (!state.denied && getSelfDc().equals("DC-A") && state.isCurrentStepApproved() && state.currentStep < maxSteps) { // approved by all, continue with next step log().info("Step {} approved by all, continue", state.currentStep); return Effect().persist(new StepStarted(state.currentStep + 1)); } else return Effect().none(); } else { return Effect().none(); } } }
The Auction Example is also using triggers.
Failures
If persistence of an event fails the problem is logged and the actor will unconditionally be stopped.
The reason that it cannot resume when persist fails is that it is unknown if the event was actually persisted or not, and therefore it is in an inconsistent state. Restarting on persistent failures will most likely fail anyway since the journal is probably unavailable. It is better to stop the actor and after a back-off timeout start it again. The akka.pattern.BackoffSupervisor actor is provided to support such restarts.
See Akka documentation of how to use the BackoffSupervisor.
Snapshots
When the entity is started the state is recovered by replaying stored events. To reduce this recovery time the entity may start the recovery from a snapshot of the state and then only replaying the events that were stored after the snapshot for that entity.
Such snapshots are automatically saved after a configured number of persisted events. The snapshot if any is automatically used as the initial state before replaying the events. The interval between snapshots can be configured with the akka.persistence.multi-data-center.snapshot-after setting.
The state must be immutable to avoid concurrency issues that may occur from changing a state instance that is about to be saved as a snapshot.
The snapshot contains internal state and user-defined state. You need to create a serializer for the state, because it is stored as snapshot. We recommend against using Java serialization. When picking serialization solution for the snapshot you should also consider that it might be necessary to read old snapshots when the application has evolved. Strategies for that can be found in the Akka documentation. It is not mandatory to be able to read old snapshots. If it fails it will instead replay more old events, which might have a performance cost.
The snapshots are local to the data center and not transferred or used across different data centers.
Passivating and stopping entities
When a ReplicatedEntity is not used it is good to stop it to reduce resource consumption. A started entity is not only using memory but also looking for new replicated events from other data centers once in a while (cassandra-journal-multi-dc.low-frequency-read-events-interval config).
When run under sharding the entities will automatically shutdown after an idle period of 90 seconds during which the entity did not receive any commands (configurable through akka.persistence.multi-data-center.auto-passivate-after). Note that this should be set higher than keep-alive.start-entity-interval if keep-alive is enabled to avoid the entities repeatedly passivating and then being restarted by the keep-alive.
If a ReplicatedEntity at some point explicitly sets a receive timeout that will cause the auto passivation to be disabled for that entity. You can programmatically disable the auto passivation for an entity by setting the receive timeout to Duration.Inf().
To explicitly passivate an entity running under Cluster Sharding you can use Effect().passivate(new YourOwnStopCommand) which will do a graceful shutdown and send YourOwnStopCommand to the entity when it is safe to stop, it can then return Effect().stop() to actually stop the entity. It is important to do this graceful shutdown dance as sharding may have buffered messages which could otherwise be lost. You can read more about the reason for passivate in the Cluster Sharding docs.
For an entity whose lifecycle you are managing yourself you can use Effect.stop directly.
Tagging Events
It is possible to “tag” events along with persisting them. This is useful for later retrival of events for a given tag. The ReplicatedEntity provides a built-in API to allow tagging before sending an event to the underlying datastore. Tagging is useful in practice to build queries that lead to other data representations or aggregations of the these event streams that can more directly serve user queries – known as building the “read side” in CQRS based applications.
In order to tag events you have to override the tagsFor method, which should return a Set of Strings, which are the tags which should be applied to this event. Returning an empty Set means no tags should be applied to this event. This method is invoked in all datacenters, as the tags could be dependent on the datacenter. For example, if the datacenter split is done to separate the cluster into regions like countries for example, and only a specific datacenter (or country) should handle some specific events, you could implement it here by inspecting the EventTaggingContext.
Most often however, you will want to tag events only in a specific Dc, or only in the origin datacenter where an event was created initially, and not tag it again in the other datacenters, to which the event will be replicated. This is avoid “double tagging” an event that is replicated to an ReplicatedEntity, and was already tagged in its origin, which could lead to seeminly “duplicated” events when querying by tag.
- Scala
- Java
-
import akka.NotUsed; import akka.actor.ActorSystem; import akka.persistence.cassandra.query.javadsl.CassandraReadJournal; import akka.persistence.multidc.PersistenceMultiDcSettings; import akka.persistence.multidc.ReplicatedEvent; import akka.persistence.multidc.crdt.Counter; import akka.persistence.multidc.javadsl.CommandHandler; import akka.persistence.multidc.javadsl.EventHandler; import akka.persistence.multidc.javadsl.ReplicatedEntity; import akka.persistence.query.EventEnvelope; import akka.persistence.query.Offset; import akka.persistence.query.PersistenceQuery; import akka.stream.ActorMaterializer; import akka.stream.javadsl.*; import java.util.Collections; import java.util.HashSet; import java.util.Set; static interface Command { } final static class Insert implements Command { public final int i; public final String note; public Insert(int i, String note) { this.i = i; this.note = note; } } static interface Event { } final class Incremented implements Event { public final int i; public final String note; public Incremented(int i, String note) { this.i = i; this.note = note; } } final class SpecialIncremented implements Event { public final Incremented i; public SpecialIncremented(Incremented i) { this.i = i; } } static class TaggingCounter extends ReplicatedEntity<Command, Event, Counter> { @Override public Counter initialState() { return Counter.empty(); } @Override public CommandHandler<Command, Event, Counter> commandHandler() { return commandHandlerBuilder(Command.class) .matchCommand(Insert.class, (ctx, state, command) -> { return Effect().none(); }) .matchAny((ctx, state, cmd) -> Effect().unhandled()); } @Override public EventHandler<Event, Counter> eventHandler() { return eventHandlerBuilder(Event.class) .matchEvent(Incremented.class, (state, evt) -> { return state.applyOperation(new Counter.Updated(evt.i)); }) .build(); } @Override public Set<String> tagsFor(EventTaggingContext ctx, Event event) { if (!ctx.isSelfOriginDc()) { // don't apply tags if event was replicated here, it already will appear in queries by tag // as the origin Dc would have tagged it already return Collections.emptySet(); } else { if (event instanceof Incremented) { // tag with the "entity type name" return Collections.singleton("TaggingCounter"); } else if (event instanceof SpecialIncremented) { // tag with entity type, and additional tag Set<String> tags = new HashSet<>(); tags.add("TaggingCounter"); tags.add("special"); return tags; } else { // do not tag other events return Collections.emptySet(); } } } }
While the above example showcases various ways of tagging, the most common and simple way to tag events is to tag them using the entity type name that is persisting these events, and doing so only in the origin datacenter, which is as simple as:
- Scala
- Java
-
abstract class SimpleTaggingCounter extends ReplicatedEntity<Command, Event, Counter> { @Override public Set<String> tagsFor(EventTaggingContext ctx, Event event) { if (ctx.isSelfOriginDc()) return Collections.singleton("TaggingCounter"); else return Collections.emptySet(); } }
You can then use Akka Persistence Query to get an Akka Stream of all the events tagged using a given tag. While events will arrive from different persistenceIds, since many entities may be tagging their events using the same tag, the ordering guarantee that Akka provides is that for each persistenceId the events will be in-order, without gaps or loss during the replay. This is made possible by taking extra caution during storage and replay of such events in Persistence Query and currently is implemented by the Cassandra journal.
- Scala
- Java
-
final ActorSystem system = ActorSystem.create("TagQueryExample"); final ActorMaterializer mat = ActorMaterializer.create(system); // obtain the queries object (which is safe to re-use) final String ReplicatedEventsQueryJournalId = PersistenceMultiDcSettings.DefaultReplicatedEventsQueryJournalPluginId(); final CassandraReadJournal queries = PersistenceQuery.get(system).readJournalFor(ReplicatedEventsQueryJournalId); // prepare a query by specific tag: final Source<EventEnvelope, NotUsed> taggingCounterEvents = queries.eventsByTag("TaggingCounter", Offset.noOffset()); // execute the query and do things with the queries events: taggingCounterEvents.runWith(Sink.foreach((EventEnvelope envelope) -> { if (envelope.event() instanceof ReplicatedEvent) { @SuppressWarnings("unchecked") ReplicatedEvent<Event> replicatedEvent = (ReplicatedEvent<Event>) envelope.event(); if (replicatedEvent.event() instanceof Incremented) { Incremented incremented = (Incremented) replicatedEvent.event(); int i = incremented.i; System.out.println(String.format("Event: Incremented by %s $note from %s for %s", i, replicatedEvent.originDc(), replicatedEvent.entityId())); } else { // unknown event... } } else { // even not stored by ReplicatedEntity, e.g. by old PersistentActor } }), mat);
You can read more about the exact semantics of the stream in the section explaining Read Journals of the Akka documentation. The short version is that two kinds of queries exist, one that is “infinite” and continues running forever, emitting new events as they are tagged (eventsByTag), and one finite that will emit all events with a given tag at a certain point in time and then complete the Source (currentEventsByTag).
Testing
See Testing.
How it works
You don’t have to read this section to be able to use the feature, but to use the abstraction efficiently and for the right type of use cases it can be good to understand how it’s implemented. For example, it should give you the right expectations of the overhead that the solution introduces compared to using plain Akka Persistence in one data center.
Storage and replication
To understand how the storage and replication works in Cassandra see here.
Causal delivery order
Causal delivery order means that events persisted in one data center are read in the same order in other data centers. The order of concurrent events is undefined, which should be no problem when using CRDT’s and otherwise will be detected.
For example:
DC-1: write e1
DC-2: read e1, write e2
DC-1: read e2, write e3
In the above example the causality is e1 -> e2 -> e3. Also in a third data center DC-3 these events will be read in the same order e1, e2, e3.
Another example with concurrent events:
DC1: write e1
DC2: read e1, write e2
DC1: write e3 (e2 and e3 are concurrent)
DC1: read e2
DC2: read e3
e2 and e3 are concurrent, i.e. they don’t have a causal relation: DC1 sees them in the order “e1, e3, e2”, while DC2 sees them as “e1, e2, e3”.
A third data center may also see the events as either “e1, e3, e2” or as “e1, e2, e3”.
Concurrent updates
The ReplicatedEntity is automatically tracking causality between events from different data centers using version vectors.
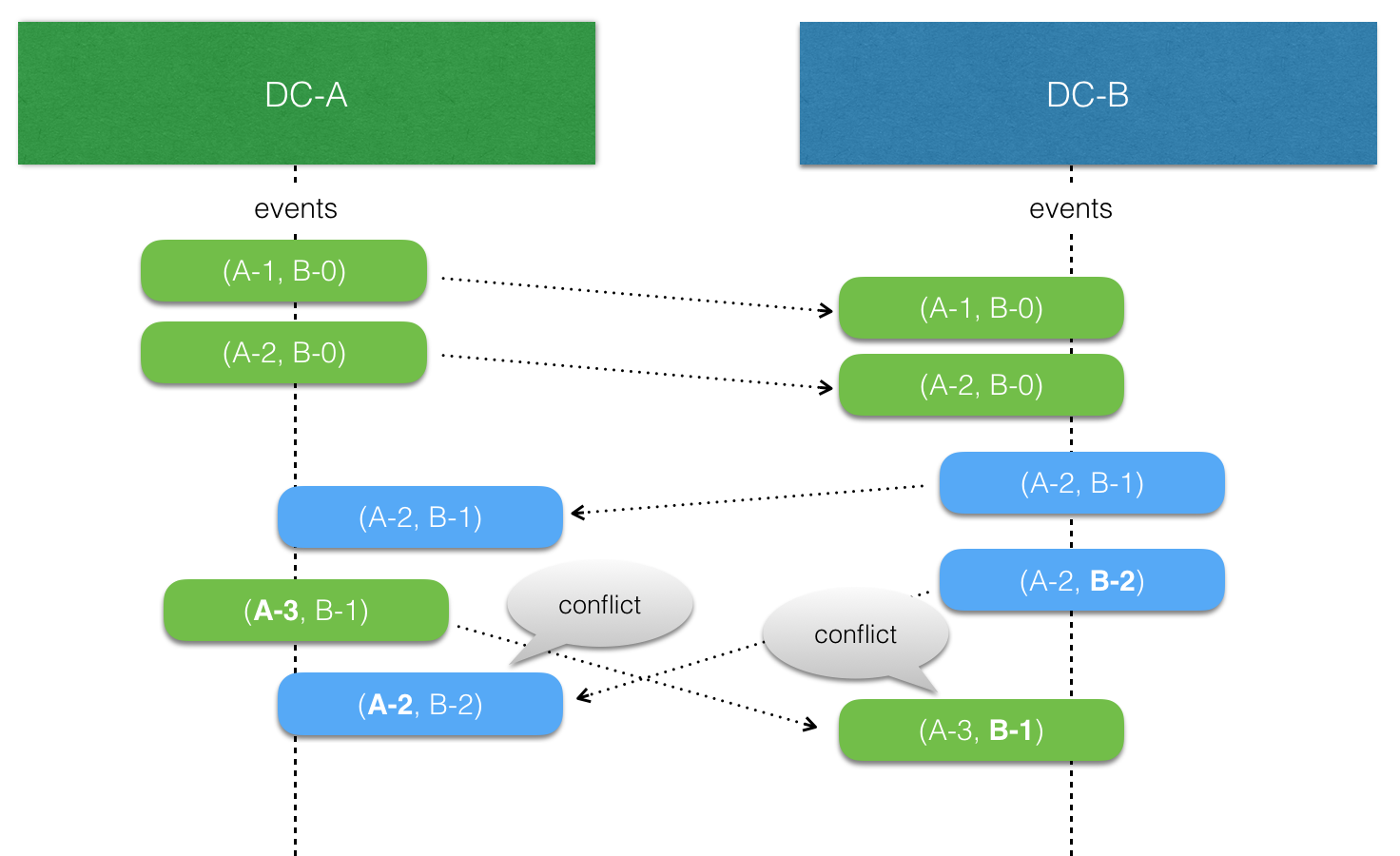
Each data center “owns” a slot in the version vector and increases its counter when an event is persisted. The version vector is stored with the event, and when a replicated event is consumed the version vector of the event is merged with the local version vector.
When comparing two version vectors v1 and v2 get one of the following results:
v1is SAME asv2iff for all i v1(i) == v2(i)v1is BEFOREv2iff for all i v1(i) <= v2(i) and there exist a j such that v1(j) < v2(j)v1is AFTERv2iff for all i v1(i) >= v2(i) and there exist a j such that v1(j) > v2(j)v1is CONCURRENT withv2otherwise
Hot-standby
If all writes occur in one data center the corresponding entity in another data center is not started there might be many replicated events to catch up with when it’s later started. Therefore it’s good to activate ReplicatedEntity instances in all data centers when there is some activity.
This is done automatically when Cluster Sharding is used. It is important that you handle the ShardRegion.StartEntity message in the shard id extractor as shown in this example.
If this is not desired it can be disabled with config property:
akka.persistence.multi-data-center.hot-standby.enabled = off
Speculative Replication Optimization
As described in Storage and replication many requests to Cassandra will be generated for retrieving the replicated events. To reduce the number of such queries and to have faster replication there is an optional replication mechanism that is sending events over Akka Cluster communication.
This speculative replication is enabled by config property:
akka.persistence.multi-data-center.speculative-replication.enabled = on
The Akka Cluster that spans multiple data centers must be setup according to the Akka Multi-DC Clustering documentation.
It requires that you are using Cluster Sharding and that you handle the akka.persistence.multidc.SpeculativeReplicatedEvent message in your entity and shard id extractors.
Additionally, you have to start Cluster Sharding proxies to the other data centers because the events are sent directly to the corresponding entity in other data centers using these proxies. That is also the reason why you have to handle the SpeculativeReplicatedEvent in the extractors.
A complete example of how to initialize Cluster Sharding looks like this:
- Scala
- Java
-
import akka.cluster.sharding.ClusterSharding; import akka.cluster.sharding.ClusterShardingSettings; import akka.cluster.sharding.ShardRegion; ShardRegion.MessageExtractor messageExtractor = new ShardRegion.MessageExtractor() { @Override public String entityId(Object message) { if (message instanceof BlogCommands.BlogCommand) { return ((BlogCommands.BlogCommand) message).getPostId(); } else if (message instanceof SpeculativeReplicatedEvent) { return ((SpeculativeReplicatedEvent) message).entityId(); } else { return null; } } @Override public Object entityMessage(Object message) { return message; } private String shardId(String entityId) { int maxNumberOfShards = 1000; return Integer.toString(Math.abs(entityId.hashCode()) % maxNumberOfShards); } @Override public String shardId(Object message) { if (message instanceof BlogCommands.BlogCommand) { return shardId(((BlogCommands.BlogCommand) message).getPostId()); } else if (message instanceof SpeculativeReplicatedEvent) { return shardId(((SpeculativeReplicatedEvent) message).entityId()); } else if (message instanceof ShardRegion.StartEntity) { return shardId(((ShardRegion.StartEntity) message).entityId()); } else { return null; } } }; String ShardingTypeName = "blog"; Props props = ReplicatedEntity.clusterShardingProps( BlogCommands.BlogCommand.class, ShardingTypeName, Post2::new, persistenceMultiDcSettings); ClusterShardingSettings settings = ClusterShardingSettings.create(system); ActorRef region = ClusterSharding.get(system).start( ShardingTypeName, props, settings, messageExtractor); if (persistenceMultiDcSettings.useSpeculativeReplication()) { for (String otherDc: persistenceMultiDcSettings.getOtherDcs(cluster.selfDataCenter())) { ClusterSharding.get(system).startProxy( ShardingTypeName, Optional.empty(), Optional.of(otherDc), messageExtractor ); } } region.tell( new BlogCommands.AddPost( "post-1", new BlogState.PostContent("First post", "...")), sender);
It’s a best-effort optimization and if the messages are not delivered this way they will eventually be delivered by the Cassandra replication, i.e. it is not a replacement for the Cassandra replication.
A tradeoff when enabling this optimization is that more messages will be sent over Akka remoting, across data centers. The total number of remote messages generated for each persisted event is (N-1) * N, if N is number of data centers. For example 6 messages for each persisted event when using 3 data centers.
Migration from/to PersistentActor
It can be reassuring to know that it is possible to migrate between plain Akka Persistence and Akka Multi-DC Persistence, in both directions.
The APIs are different so migration of the source code requires some effort but should be rather straightforward since the all features exist in both APIs. More important is migration of the data.
You might have an existing system that is built with Akka’s PersistentActor and you would like to migrate to Multi-DC Persistence and still use the old data. After using ReplicatedEntity it might turn out that you don’t want to use it any more and then you can migrate back to plain Akka Persistence and still use the data stored by Multi-DC Persistence.
All these migration scenarios are possible without any risk of data loss.
The reason this is possible is that the ReplicatedEntity is implemented with an underlying PersistentActor and the ordinary akka-persistence-cassandra plugin is used as journal backend.
PersistentActor to ReplicatedEntity
The persistenceId of a ReplicatedEntity is by default the concatenation of persistenceIdPrefix, entityId and the data center identifier, separated with |. The old persistenceId doesn’t contain the data center part and therefore you must pick one data center that will host the old data and override persistenceId to specify the old persistenceId for that data center. For other data centers you can use the default format.
- Scala
- Java
-
class SomeReplicatedEntity extends ReplicatedEntity<BlogCommands.BlogCommand, BlogEvents.BlogEvent, BlogState> { // Migration from PersistentActor @Override public String persistenceId(String persistenceIdPrefix, String entityId, String dc) { if (dc.equals("DC-A")) { // different separator, no dc suffix return persistenceIdPrefix + "-" + entityId; } else { return super.persistenceId(persistenceIdPrefix, entityId, dc); } } }
The new ReplicatedEntity will be able to read old events and those will be replicated over to other data centers. Since it can be much data to replicate it is good to let the system perform this replication by gradually starting/stopping entities in all data centers.
Old snapshots can also be read but it is only events that are replicated. That could be a problem if you have removed old events and only rely on snapshots. Then you have to manually copy the old snapshots to the corresponding new persistenceId in other data centers. The new persistenceId format is persistenceIdPrefix|entityId|dc as described above.
If the old snapshot type doesn’t match the new State type you can convert the old snapshots by overriding the metod snapshotMigration in the ReplicatedEntity.
ReplicatedEntity to PersistentActor
It is also possible for a PersistentActor to read events stored by ReplicatedEntity. The event log for one data center is complete, i.e. it contains all events including the consumed replicated events that were originally stored in another data center. Therefore you can pick one of the persistenceId for an entity. Corresponding persistenceId for other data centers contains the same events and are therefore redundant when migrating to PersistentActor in a single data center.
However, there is additional meta data stored with the event, such as:
timestamp- time when the event was persistedoriginDcthe event was persisted by this data centerversionVectorthat is used for theconcurrentflag, see Detecting concurrent updates
Note that this meta data is stored in the meta column in the journal (messages) table used by akka-persistence-cassandra. The reason for storing the meta data in a separate column instead of wrapping the original event is that it should be seamless to migrate away from this tool, if needed, and still be able to read the events without any additional dependencies.
If the meta data has been used for deciding how to apply events to the state in the eventHandler you must rewrite the events to include that information in the original events. That can be done using Akka Streams or Spark and we will add more detailed advice and perhaps some tooling of how to do that in the future (or on Customer demanand).
Snapshots stored by ReplicatedEntity are of the class akka.persistence.multidc.ReplicatedEntitySnapshot. You can consume those snapshots in a PersistentActor but to remove the dependency to that class you have to store your own snapshot after recovery of PersistentActor that had such a ReplicatedEntitySnapshot. Thereafter you can remove the old snapshots. An alternative is to remove the snapshots alltogether and replay all events.
Configuration
Example of the most important settings, including settings from other related Akka libraries:
akka.actor {
provider = cluster
}
akka.remote {
netty.tcp {
# Change this to real hostname for production
hostname = "host1"
port = 2552
}
}
akka.cluster {
# Change this to real hostname for production
seed-nodes = ["akka.tcp://ClusterSystem@host1:2552", "akka.tcp://ClusterSystem@host2:2552"]
# Change this to the Akka data center this node belongs to
multi-data-center.self-data-center = DC-A
}
akka.persistence {
snapshot-store.plugin = "cassandra-snapshot-store"
multi-data-center {
all-data-centers = ["DC-A", "DC-B"]
}
}
cassandra-journal-multi-dc {
# Change this to real hostname for production
contact-points = ["host3", "host4"]
# Port of contact points in the Cassandra cluster.
port = 9042
keyspace = "myapp"
replication-strategy = "NetworkTopologyStrategy"
# Replication factor list for data centers
data-center-replication-factors = ["dc1:3", "dc2:3"]
# Change this to the Cassandra data center this node belongs to,
# note that Akka data center identifiers and Cassandra data center
# identifiers are not the same.
local-datacenter = "dc1"
}
A full reference of the configuration settings available can be found here:
akka.persistence.multi-data-center {
all-data-centers = []
# Configuration id of the journal plugin servicing replicated persistent actors.
# When configured, uses this value as absolute path to the journal configuration entry.
# Configuration entry must contain few required fields, such as `class`.
# See `src/main/resources/reference.conf` in akka-persistence.
journal-plugin-id = "cassandra-journal-multi-dc"
replicated-events-query-journal-plugin-id = "cassandra-query-journal-multi-dc"
# Keeping many ReplicatedEntities alive is expensive, both memory wise and that it checks
# for events in the other data centers every now and then. When using sharding this timeout makes the
# entity passivate when it has not seen any messages for a while. Set to "off" to disable the automatic
# passivation. If sharding is not used, this setting is not applied, to do the corresponding thing for entities
# used without sharding, you can manually set a receive timeout and stop the entity when it hits.
# Note that this should be set higher than `keep-alive.start-entity-interval` if `keep-alive` is enabled to avoid
# the entities repeatedly passivating and then being restarted by the keep-alive.
auto-passivate-after = 90 s
# Optimization to also send events directly to entities in other data centers,
# which can be faster than the Cassandra replication and reduce the need for
# reading the events from Cassandra in the other data centers.
# It's a best-effort optimization and if the message is not delivered it
# will eventually be delivered by the Cassandra replication.
speculative-replication {
enabled = off
}
# You can configure Multi-DC persistence to use a separate Cassandra cluster for
# each data center and not use Cassandra's data center replication for the events.
# The events are then retrieved from another data center with ordinary Cassandra
# queries to the Cassandra cluster in the other data center.
cross-reading-replication {
# Set this to on to enable the cross reading mode.
enabled = off
# This can be set to on to disable cross reading of the notifications table
# and instead read it from the local Cassandra cluster. That means
# that the notifications table must be replicated by Cassandra, which is done by
# having that table in a separate keyspace with Cassandra replication settings:
# cassandra-journal-multi-dc.notification.keyspace and
# cassandra-journal-multi-dc.notification.data-center-replication-factors
local-notification = off
cassandra-journal {
# One section per DC that defines the contact-points, keyspace and such of that DC,
# for example:
#
# contact-points = ["eu-west-node1", "eu-west-node2"]
# keyspace = "akka_west"
# local-datacenter = "eu-west"
# data-center-replication-factors = ["eu-west:3"]
#}
# contact-points = ["eu-central-node1", "eu-central-node2"]
# keyspace = "akka_central"
# local-datacenter = "eu-central"
# data-center-replication-factors = ["eu-central:3"]
#}
}
}
# Start ReplicatedEntity instances based on notifications from other data centers.
# If all writes occur in one data center and the corresponding entity in another data
# center is not started there might be many replicated events to catch up with when
# it is later started. Therefore it's good to activate ReplicatedEntity instances
# in all data centers when there is some activity. They can passivate themselves
# when they have been idle for a while.
hot-standby {
enabled = on
# Activate after this delay when ActorSystem is started, to avoid too much
# load when starting up
init-delay = 10 s
# How often ShardRegion.StartEntity will be sent to each entity. It is sent when
# the first notification is observed for the entityId and later additional
# notifications are ignored until the next tick.
# Passivation timeout of the entities should be longer than this duration.
start-entity-interval = 1 minute
# Run on nodes with this role. If undefined ("") it will run on all nodes independent
# of role. This should correspond to the role used for Cluster Sharding or be a subset
# of that role.
cluster-role = ""
}
# Restart of the replication streams in case of failure
replication-stream.restart-backoff {
min = 1 s
max = 20 s
}
materializer = ${akka.stream.materializer} # include default settings
materializer {
}
# If set to a value > 0, automatically take periodical snapshots after the given number of events.
# Set to 0 or 'off' to disable automatic snapshots.
snapshot-after = 100
logging {
# Causes the persistenceId which can get pretty interesting in multi-dc, e.g. `flight|UA740-test2|DC-B`
# to be included automatically in each log statement issued by the default logger provided by an ReplicatedEntity
# Available:
# - prefix -- includes the id at the beginning of log statements, for easy manual comprehention and parsing
# - mdc -- includes the id in the loggers MDC, under the `persistenceId` key
include-persistenceId = "prefix"
}
}
cassandra-journal-multi-dc = ${cassandra-journal} # include default settings
cassandra-journal-multi-dc {
class = "akka.persistence.multidc.internal.CassandraReplicatedEventJournal"
# The query journal to use when recovering
query-plugin = "cassandra-query-journal-multi-dc"
# Write consistency level
# The default read and write consistency levels ensure that persistent actors can read their own writes.
# During normal operation, persistent actors only write to the journal, reads occur only during recovery.
write-consistency = "LOCAL_QUORUM"
# Read consistency level
read-consistency = "LOCAL_QUORUM"
low-frequency-read-events-interval = 30 s
notification {
write-interval = 1 s
write-aggregation-size = 1000
read-interval = 500 ms
look-for-old = 10 minutes
publish-delay = 250 ms
additional-random-publish-delay = 250 ms
write-consistency = "ONE"
write-retries = 2
read-consistency = "ONE"
read-retries = 2
# Name of the notification table. By default this is the name of the journal
# messages table suffixed with "_notification".
table = ""
# TimeWindowCompactionStrategy reccommends no more than 50 buckets. With a TTL of 1 day and 1 hour
# we will have 24 buckets.
table-compaction-strategy {
class = "TimeWindowCompactionStrategy"
compaction_window_unit = "HOURS"
compaction_window_size = 1
}
# Purging of notification table is done with TTLs.
# Notifcations are kept for 1 day and then removed entirely one hour after via gc-grace-seconds
time-to-live = 86400
gc-grace-seconds = 3600
# Keyspace of the notification table, if different from the keyspace of the journal table.
# Use this together with:
# akka.persistence.multi-data-center.cross-reading-replication.local-notification = on
keyspace = ""
# Replication factor list for data centers when using a separate keyspace for the notification table,
# e.g. ["dc1:3", "dc2:2"]. Is only used when replication-strategy is NetworkTopologyStrategy.
# Use this together with:
# akka.persistence.multi-data-center.cross-reading-replication.local-notification = on
data-center-replication-factors = []
}
}
cassandra-query-journal-multi-dc = ${cassandra-query-journal} # include default settings
cassandra-query-journal-multi-dc {
class = "akka.persistence.multidc.internal.CassandraReadJournalProvider"
# Absolute path to the write journal plugin configuration section
write-plugin = "cassandra-journal-multi-dc"
# Read consistency level
read-consistency = "LOCAL_QUORUM"
}See also the description of the cross reading mode.
Defining the data centers
Nodes are grouped into data centers with the same configuration setting as is used for Akka Multi-DC Clustering, i.e. by setting the akka.cluster.multi-data-center.self-data-center configuration property. A node can only belong to one data center and if nothing is specified a node will belong to the default data center.
The grouping of nodes is not limited to the physical boundaries of data centers, even though that is the primary use case. It could also be used as a logical grouping for other reasons, such as isolation of certain nodes to improve stability or splitting up a large cluster into smaller groups of nodes for better scalability.
You must also define all data centers, including the self-data-center.
akka.cluster.multi-data-center.self-data-center = "DC-A"
akka.persistence.multi-data-center.all-data-centers = ["DC-A", "DC-B"]
API docs
The javadoc for the APIs can be found here: Akka Enhancements API