Substreams
Dependency
The Akka dependencies are available from Akka’s library repository. To access them there, you need to configure the URL for this repository.
- sbt
resolvers += "Akka library repository".at("https://repo.akka.io/maven")- Maven
<project> ... <repositories> <repository> <id>akka-repository</id> <name>Akka library repository</name> <url>https://repo.akka.io/maven</url> </repository> </repositories> </project>- Gradle
repositories { mavenCentral() maven { url "https://repo.akka.io/maven" } }
To use Akka Streams, add the module to your project:
- sbt
val AkkaVersion = "2.9.7" libraryDependencies += "com.typesafe.akka" %% "akka-stream" % AkkaVersion- Maven
<properties> <scala.binary.version>2.13</scala.binary.version> </properties> <dependencyManagement> <dependencies> <dependency> <groupId>com.typesafe.akka</groupId> <artifactId>akka-bom_${scala.binary.version}</artifactId> <version>2.9.7</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <dependencies> <dependency> <groupId>com.typesafe.akka</groupId> <artifactId>akka-stream_${scala.binary.version}</artifactId> </dependency> </dependencies>- Gradle
def versions = [ ScalaBinary: "2.13" ] dependencies { implementation platform("com.typesafe.akka:akka-bom_${versions.ScalaBinary}:2.9.7") implementation "com.typesafe.akka:akka-stream_${versions.ScalaBinary}" }
Introduction
Substreams are represented as SubSource or SubFlowSubFlow instances, on which you can multiplex a single SourceSource or FlowFlow into a stream of streams.
SubFlows cannot contribute to the super-flow’s materialized value since they are materialized later, during the runtime of the stream processing.
operators that create substreams are listed on Nesting and flattening operators
Nesting operators
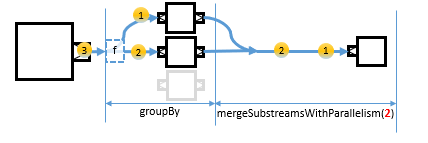
groupBy
A typical operation that generates substreams is groupBygroupBy.
- Scala
-
source
val source = Source(1 to 10).groupBy(3, _ % 3) - Java
-
source
Source.from(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)).groupBy(3, elem -> elem % 3);
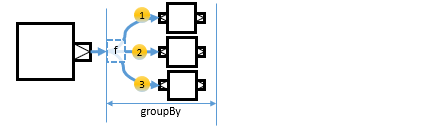
This operation splits the incoming stream into separate output streams, one for each element key. The key is computed for each element using the given function, which is f in the above diagram. When a new key is encountered for the first time a new substream is opened and subsequently fed with all elements belonging to that key. If allowClosedSubstreamRecreation is set to true a substream belonging to a specific key will be recreated if it was closed before, otherwise elements belonging to that key will be dropped.
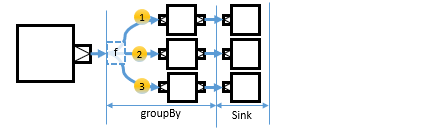
If you add a SinkSink or FlowFlow right after the groupBy operator, all transformations are applied to all encountered substreams in the same fashion. So, if you add the following Sink, that is added to each of the substreams as in the below diagram.
- Scala
-
source
Source(1 to 10).groupBy(3, _ % 3).to(Sink.ignore).run() - Java
-
source
Source.from(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)) .groupBy(3, elem -> elem % 3) .to(Sink.ignore()) .run(system);
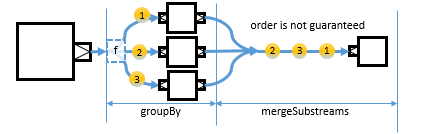
Also substreams, more precisely, SubFlowSubFlow and SubSource have methods that allow you to merge or concat substreams into the main stream again.
The mergeSubstreamsmergeSubstreams method merges an unbounded number of substreams back to the main stream.
- Scala
-
source
Source(1 to 10).groupBy(3, _ % 3).mergeSubstreams.runWith(Sink.ignore) - Java
-
source
Source.from(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)) .groupBy(3, elem -> elem % 3) .mergeSubstreams() .runWith(Sink.ignore(), system);
You can limit the number of active substreams running and being merged at a time, with either the mergeSubstreamsWithParallelismmergeSubstreamsWithParallelism or concatSubstreamsconcatSubstreams method.
- Scala
-
source
Source(1 to 10).groupBy(3, _ % 3).mergeSubstreamsWithParallelism(2).runWith(Sink.ignore) //concatSubstreams is equivalent to mergeSubstreamsWithParallelism(1) Source(1 to 10).groupBy(3, _ % 3).concatSubstreams.runWith(Sink.ignore) - Java
-
source
Source.from(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)) .groupBy(3, elem -> elem % 3) .mergeSubstreamsWithParallelism(2) .runWith(Sink.ignore(), system); // concatSubstreams is equivalent to mergeSubstreamsWithParallelism(1) Source.from(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)) .groupBy(3, elem -> elem % 3) .concatSubstreams() .runWith(Sink.ignore(), system);
However, since the number of running (i.e. not yet completed) substreams is capped, be careful so that these methods do not cause deadlocks with back pressure like in the below diagram.
Element one and two leads to two created substreams, but since the number of substreams are capped to 2 when element 3 comes in it cannot lead to creation of a new substream until one of the previous two are completed and this leads to the stream being deadlocked.
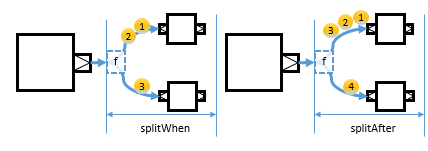
splitWhen and splitAfter
splitWhensplitWhen and splitAftersplitAfter are two other operations which generate substreams.
The difference from groupBygroupBy is that, if the predicate for splitWhen and splitAfter returns true, a new substream is generated, and the succeeding elements after split will flow into the new substream.
splitWhen flows the element on which the predicate returned true to a new substream, whereas splitAfter flows the next element to the new substream after the element on which predicate returned true.
- Scala
-
source
Source(1 to 10).splitWhen(SubstreamCancelStrategy.drain)(_ == 3) Source(1 to 10).splitAfter(SubstreamCancelStrategy.drain)(_ == 3) - Java
-
source
Source.from(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)).splitWhen(elem -> elem == 3); Source.from(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)).splitAfter(elem -> elem == 3);
These are useful when you scanned over something and you don’t need to care about anything behind it. A typical example is counting the number of characters for each line like below.
- Scala
-
source
val text = "This is the first line.\n" + "The second line.\n" + "There is also the 3rd line\n" val charCount = Source(text.toList) .splitAfter { _ == '\n' } .filter(_ != '\n') .map(_ => 1) .reduce(_ + _) .to(Sink.foreach(println)) .run() - Java
-
source
String text = "This is the first line.\n" + "The second line.\n" + "There is also the 3rd line\n"; Source.from(Arrays.asList(text.split(""))) .map(x -> x.charAt(0)) .splitAfter(x -> x == '\n') .filter(x -> x != '\n') .map(x -> 1) .reduce((x, y) -> x + y) .to(Sink.foreach(x -> System.out.println(x))) .run(system);
This prints out the following output.
23
16
26
Flattening operators
flatMapConcat
flatMapConcatflatMapConcat and flatMapMergeflatMapMerge are substream operations different from groupBygroupBy and splitWhen/After.
flatMapConcat takes a function, which is f in the following diagram. The function f of flatMapConcat transforms each input element into a SourceSource that is then flattened into the output stream by concatenation.
- Scala
-
source
Source(1 to 2).flatMapConcat(i => Source(List.fill(3)(i))).runWith(Sink.ignore) - Java
-
source
Source.from(Arrays.asList(1, 2)) .flatMapConcat(i -> Source.from(Arrays.asList(i, i, i))) .runWith(Sink.ignore(), system);
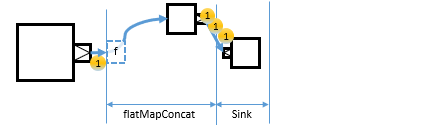
Like the concat operation on FlowFlow, it fully consumes one SourceSource after the other. So, there is only one substream actively running at a given time.
Then once the active substream is fully consumed, the next substream can start running. Elements from all the substreams are concatenated to the sink.
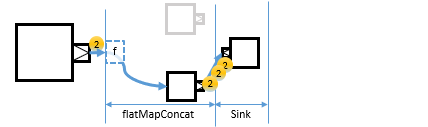
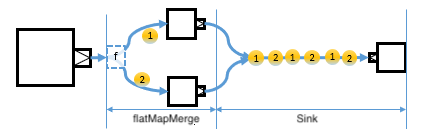
flatMapMerge
flatMapMerge is similar to flatMapConcat, but it doesn’t wait for one Source to be fully consumed. Instead, up to breadth number of streams emit elements at any given time.
- Scala
-
source
Source(1 to 2).flatMapMerge(2, i => Source(List.fill(3)(i))).runWith(Sink.ignore) - Java
-
source
Source.from(Arrays.asList(1, 2)) .flatMapMerge(2, i -> Source.from(Arrays.asList(i, i, i))) .runWith(Sink.ignore(), system);