New to Akka? Start with the Akka SDK.
Classic Actors
Akka Classic pertains to the original Actor APIs, which have been improved by more type safe and guided Actor APIs. Akka Classic is still fully supported and existing applications can continue to use the classic APIs. It is also possible to use the new Actor APIs together with classic actors in the same ActorSystem, see coexistence. For new projects we recommend using the new Actor API.
Module info
The Akka dependencies are available from Akka’s secure library repository. To access them you need to use a secure, tokenized URL as specified at https://account.akka.io/token.
To use Classic Actors, add the following dependency in your project:
- sbt
val AkkaVersion = "2.10.20+3-e75e8093-SNAPSHOT" libraryDependencies ++= Seq( "com.typesafe.akka" %% "akka-actor" % AkkaVersion, "com.typesafe.akka" %% "akka-testkit" % AkkaVersion % Test )- Maven
<properties> <scala.binary.version>2.13</scala.binary.version> </properties> <dependencyManagement> <dependencies> <dependency> <groupId>com.typesafe.akka</groupId> <artifactId>akka-bom_${scala.binary.version}</artifactId> <version>2.10.20+3-e75e8093-SNAPSHOT</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <dependencies> <dependency> <groupId>com.typesafe.akka</groupId> <artifactId>akka-actor_${scala.binary.version}</artifactId> </dependency> <dependency> <groupId>com.typesafe.akka</groupId> <artifactId>akka-testkit_${scala.binary.version}</artifactId> <scope>test</scope> </dependency> </dependencies>- Gradle
def versions = [ ScalaBinary: "2.13" ] dependencies { implementation platform("com.typesafe.akka:akka-bom_${versions.ScalaBinary}:2.10.20+3-e75e8093-SNAPSHOT") implementation "com.typesafe.akka:akka-actor_${versions.ScalaBinary}" testImplementation "com.typesafe.akka:akka-testkit_${versions.ScalaBinary}" }
| Project Info: Akka Actors (classic) | |
|---|---|
| Artifact | com.typesafe.akka
akka-actor
2.10.20+3-e75e8093-SNAPSHOT
|
| JDK versions | Eclipse Temurin JDK 11 Eclipse Temurin JDK 17 Eclipse Temurin JDK 21 |
| Scala versions | 2.13.17, 3.3.7 |
| JPMS module name | akka.actor |
| License | |
| Readiness level |
Since 2.0, 2012-03-06
|
| Home page | https://akka.io/ |
| API documentation | |
| Forums | |
| Release notes | Akka release notes |
| Issues | Github issues |
| Sources | https://github.com/akka/akka-core |
Introduction
The Actor Model provides a higher level of abstraction for writing concurrent and distributed systems. It alleviates the developer from having to deal with explicit locking and thread management, making it easier to write correct concurrent and parallel systems. Actors were defined in the 1973 paper by Carl Hewitt but have been popularized by the Erlang language and used for example at Ericsson with great success to build highly concurrent and reliable telecom systems.
The API of Akka’s Actors is similar to Scala Actors which has borrowed some of its syntax from Erlang.
Creating Actors
Since Akka enforces parental supervision every actor is supervised and (potentially) the supervisor of its children, it is advisable to familiarize yourself with Actor Systems, supervision and handling exceptions as well as Actor References, Paths and Addresses.
Defining an Actor class
Actors are implemented by extending the Actor base trait and implementing the receive method. The receive method should define a series of case statements (which has the type PartialFunction[Any, Unit]) that define which messages your Actor can handle, using standard Scala pattern matching, along with the implementation of how the messages should be processed.
Actor classes are implemented by extending the AbstractActor class and setting the “initial behavior” in the createReceive method.
The createReceive method has no arguments and returns AbstractActor.Receive. It defines which messages your Actor can handle, along with the implementation of how the messages should be processed. You can build such behavior with a builder named ReceiveBuilder. This build has a convenient factory in AbstractActor called receiveBuilder.
Here is an example:
- Scala
-
source
import akka.actor.Actor import akka.actor.Props import akka.event.Logging class MyActor extends Actor { val log = Logging(context.system, this) def receive = { case "test" => log.info("received test") case _ => log.info("received unknown message") } } - Java
-
source
import akka.actor.AbstractActor; import akka.event.Logging; import akka.event.LoggingAdapter; public class MyActor extends AbstractActor { private final LoggingAdapter log = Logging.getLogger(getContext().getSystem(), this); @Override public Receive createReceive() { return receiveBuilder() .match( String.class, s -> { log.info("Received String message: {}", s); }) .matchAny(o -> log.info("received unknown message")) .build(); } }
Please note that the Akka Actor receive message loop is exhaustive, which is different compared to Erlang and the late Scala Actors. This means that you need to provide a pattern match for all messages that it can accept and if you want to be able to handle unknown messages then you need to have a default case as in the example above. Otherwise an UnhandledMessageUnhandledMessage will be published to the ActorSystemActorSystem’s EventStreamEventStream.
Note further that the return type of the behavior defined above is Unit; if the actor shall reply to the received message then this must be done explicitly as explained below.
The result of the receive method is a partial function object, which is createReceive method is AbstractActor.Receive which is a wrapper around partial scala function object. It is stored within the actor as its “initial behavior”, see Become/Unbecome for further information on changing the behavior of an actor after its construction.
Props
PropsProps is a configuration class to specify options for the creation of actors, think of it as an immutable and thus freely shareable recipe for creating an actor including associated deployment information (e.g., which dispatcher to use, see more below). Here are some examples of how to create a Props instance.
- Scala
-
source
import akka.actor.Props val props1 = Props[MyActor]() val props2 = Props(new ActorWithArgs("arg")) // careful, see below val props3 = Props(classOf[ActorWithArgs], "arg") // no support for value class arguments - Java
-
source
import akka.actor.Props; Props props1 = Props.create(MyActor.class); Props props2 = Props.create(ActorWithArgs.class, () -> new ActorWithArgs("arg")); // careful, see below Props props3 = Props.create(ActorWithArgs.class, "arg");
The second variant shows how to pass constructor arguments to the ActorActor being created, but it should only be used outside of actors as explained below.
The last line shows a possibility to pass constructor arguments regardless of the context it is being used in. The presence of a matching constructor is verified during construction of the Props object, resulting in an IllegalArgumentException if no or multiple matching constructors are found.
The recommended approach to create the actor PropsProps is not supported for cases when the actor constructor takes value classes as arguments.
Dangerous Variants
- Scala
-
source
// NOT RECOMMENDED within another actor: // encourages to close over enclosing class val props7 = Props(new MyActor) - Java
-
source
// NOT RECOMMENDED within another actor: // encourages to close over enclosing class Props props7 = Props.create(ActorWithArgs.class, () -> new ActorWithArgs("arg"));
This method is not recommended being used within another actor because it encourages to close over the enclosing scope, resulting in non-serializable Props and possibly race conditions (breaking the actor encapsulation). On the other hand, using this variant in a Props factory in the actor’s companion object as documented under “Recommended Practices” below is completely fine.
There were two use-cases for these methods: passing constructor arguments to the actor—which is solved by the newly introduced Props.apply(clazz, args) Props.create(clazz, args) method above or the recommended practice below—and creating actors “on the spot” as anonymous classes. The latter should be solved by making these actors named classes instead (if they are not declared within a top-level object then the enclosing instance’s this reference needs to be passed as the first argument).
Declaring one actor within another is very dangerous and breaks actor encapsulation. Never pass an actor’s this reference into Props!
Edge cases
There are two edge cases in actor creation with akka.actor.Props:
- An actor with
AnyValarguments.
sourcecase class MyValueClass(v: Int) extends AnyVal
sourceclass ValueActor(value: MyValueClass) extends Actor {
def receive = {
case multiplier: Long => sender() ! (value.v * multiplier)
}
}
val valueClassProp = Props(classOf[ValueActor], MyValueClass(5)) // Unsupported
- An actor with default constructor values.
sourceclass DefaultValueActor(a: Int, b: Int = 5) extends Actor {
def receive = {
case x: Int => sender() ! ((a + x) * b)
}
}
val defaultValueProp1 = Props(classOf[DefaultValueActor], 2.0) // Unsupported
class DefaultValueActor2(b: Int = 5) extends Actor {
def receive = {
case x: Int => sender() ! (x * b)
}
}
val defaultValueProp2 = Props[DefaultValueActor2]() // Unsupported
val defaultValueProp3 = Props(classOf[DefaultValueActor2]) // Unsupported
In both cases, an IllegalArgumentException will be thrown stating no matching constructor could be found.
The next section explains the recommended ways to create Actor props in a way, which simultaneously safe-guards against these edge cases.
Recommended Practices
It is a good idea to provide factory methods on the companion object of each ActorActor static factory methods for each ActorActor which help keeping the creation of suitable Props as close to the actor definition as possible. This also avoids the pitfalls associated with using the Props.apply(...) method which takes a by-name argument, since within a companion object Props.create(...) method which takes arguments as constructor parameters, since within static method the given code block will not retain a reference to its enclosing scope:
- Scala
-
source
object DemoActor { /** * Create Props for an actor of this type. * * @param magicNumber The magic number to be passed to this actor’s constructor. * @return a Props for creating this actor, which can then be further configured * (e.g. calling `.withDispatcher()` on it) */ def props(magicNumber: Int): Props = Props(new DemoActor(magicNumber)) } class DemoActor(magicNumber: Int) extends Actor { def receive = { case x: Int => sender() ! (x + magicNumber) } } @nowarn("msg=never used") // sample snippets class SomeOtherActor extends Actor { // Props(new DemoActor(42)) would not be safe context.actorOf(DemoActor.props(42), "demo") // ... } - Java
-
source
static class DemoActor extends AbstractActor { /** * Create Props for an actor of this type. * * @param magicNumber The magic number to be passed to this actor’s constructor. * @return a Props for creating this actor, which can then be further configured (e.g. calling * `.withDispatcher()` on it) */ static Props props(Integer magicNumber) { // You need to specify the actual type of the returned actor // since Java 8 lambdas have some runtime type information erased return Props.create(DemoActor.class, () -> new DemoActor(magicNumber)); } private final Integer magicNumber; public DemoActor(Integer magicNumber) { this.magicNumber = magicNumber; } @Override public Receive createReceive() { return receiveBuilder() .match( Integer.class, i -> { getSender().tell(i + magicNumber, getSelf()); }) .build(); } } static class SomeOtherActor extends AbstractActor { // Props(new DemoActor(42)) would not be safe ActorRef demoActor = getContext().actorOf(DemoActor.props(42), "demo"); // ... }
Another good practice is to declare what messages an Actor can receive in the companion object of the Actor as close to the actor definition as possible (e.g. as static classes inside the Actor or using other suitable class), which makes easier to know what it can receive:
- Scala
-
source
object MyActor { case class Greeting(from: String) case object Goodbye } class MyActor extends Actor with ActorLogging { import MyActor._ def receive = { case Greeting(greeter) => log.info(s"I was greeted by $greeter.") case Goodbye => log.info("Someone said goodbye to me.") } } - Java
-
source
static class DemoMessagesActor extends AbstractLoggingActor { public static class Greeting { private final String from; public Greeting(String from) { this.from = from; } public String getGreeter() { return from; } } @Override public Receive createReceive() { return receiveBuilder() .match( Greeting.class, g -> { log().info("I was greeted by {}", g.getGreeter()); }) .build(); } }
Creating Actors with Props
Actors are created by passing a PropsProps instance into the actorOf factory method which is available on ActorSystemActorSystem and ActorContextActorContext.
- Scala
-
source
import akka.actor.ActorSystem // ActorSystem is a heavy object: create only one per application val system = ActorSystem("mySystem") val myActor = system.actorOf(Props[MyActor](), "myactor2") - Java
-
source
import akka.actor.ActorRef; import akka.actor.ActorSystem;
Using the ActorSystem will create top-level actors, supervised by the actor system’s provided guardian actor while using an actor’s context will create a child actor.
- Scala
-
source
class FirstActor extends Actor { val child = context.actorOf(Props[MyActor](), name = "myChild") def receive = { case x => sender() ! x } } - Java
-
source
static class FirstActor extends AbstractActor { final ActorRef child = getContext().actorOf(Props.create(MyActor.class), "myChild"); @Override public Receive createReceive() { return receiveBuilder().matchAny(x -> getSender().tell(x, getSelf())).build(); } }
It is recommended to create a hierarchy of children, grand-children and so on such that it fits the logical failure-handling structure of the application, see Actor Systems.
The call to actorOf returns an instance of ActorRefActorRef. This is a handle to the actor instance and the only way to interact with it. The ActorRef is immutable and has a one to one relationship with the Actor it represents. The ActorRef is also serializable and network-aware. This means that you can serialize it, send it over the wire and use it on a remote host, and it will still be representing the same Actor on the original node, across the network.
The name parameter is optional, but you should preferably name your actors, since that is used in log messages and for identifying actors. The name must not be empty or start with $, but it may contain URL encoded characters (eg., %20 for a blank space). If the given name is already in use by another child to the same parent an InvalidActorNameExceptionInvalidActorNameException is thrown.
Actors are automatically started asynchronously when created.
Value classes as constructor arguments
The recommended way to instantiate actor props uses reflection at runtime to determine the correct actor constructor to be invoked and due to technical limitations it is not supported when said constructor takes arguments that are value classes. In these cases you should either unpack the arguments or create the props by calling the constructor manually:
sourceclass Argument(val value: String) extends AnyVal
class ValueClassActor(arg: Argument) extends Actor {
def receive = { case _ => () }
}
object ValueClassActor {
def props1(arg: Argument) = Props(classOf[ValueClassActor], arg) // fails at runtime
def props2(arg: Argument) = Props(classOf[ValueClassActor], arg.value) // ok
def props3(arg: Argument) = Props(new ValueClassActor(arg)) // ok
}Dependency Injection
If your ActorActor has a constructor that takes parameters then those need to be part of the PropsProps as well, as described above. But there are cases when a factory method must be used, for example when the actual constructor arguments are determined by a dependency injection framework.
- Scala
-
source
import akka.actor.IndirectActorProducer class DependencyInjector(applicationContext: AnyRef, beanName: String) extends IndirectActorProducer { override def actorClass = classOf[Actor] override def produce() = new Echo(beanName) def this(beanName: String) = this("", beanName) } val actorRef: ActorRef = system.actorOf(Props(classOf[DependencyInjector], applicationContext, "hello"), "helloBean") - Java
-
source
import akka.actor.Actor; import akka.actor.IndirectActorProducer; class DependencyInjector implements IndirectActorProducer { final Object applicationContext; final String beanName; public DependencyInjector(Object applicationContext, String beanName) { this.applicationContext = applicationContext; this.beanName = beanName; } @Override public Class<? extends Actor> actorClass() { return TheActor.class; } @Override public TheActor produce() { TheActor result; result = new TheActor((String) applicationContext); return result; } } final ActorRef myActor = getContext() .actorOf( Props.create(DependencyInjector.class, applicationContext, "TheActor"), "TheActor");
You might be tempted at times to offer an IndirectActorProducerIndirectActorProducer which always returns the same instance, e.g. by using a lazy val. static field. This is not supported, as it goes against the meaning of an actor restart, which is described here: What Restarting Means.
When using a dependency injection framework, actor beans MUST NOT have singleton scope.
Techniques for dependency injection and integration with dependency injection frameworks are described in more depth in the Using Akka with Dependency Injection guideline and the Akka Java Spring tutorial.
Actor API
The ActorActor trait defines only one abstract method, the above mentioned receive, which implements the behavior of the actor. The AbstractActorAbstractActor class defines a method called createReceive, that is used to set the “initial behavior” of the actor.
If the current actor behavior does not match a received message, unhandled is called, which by default publishes an akka.actor.UnhandledMessage(message, sender, recipient)akka.actor.UnhandledMessage(message, sender, recipient) on the actor system’s event stream (set configuration item akka.actor.debug.unhandled to on to have them converted into actual Debug messages).
In addition, it offers:
selfgetSelf()reference to theActorRefActorRefof the actorsendergetSender()reference sender Actor of the last received message, typically used as described in Actor.Reply LambdaActor.ReplysupervisorStrategysupervisorStrategy()user overridable definition the strategy to use for supervising child actors
This strategy is typically declared inside the actor to have access to the actor’s internal state within the decider function: since failure is communicated as a message sent to the supervisor and processed like other messages (albeit outside the normal behavior), all values and variables within the actor are available, as is the sender reference (which will be the immediate child reporting the failure; if the original failure occurred within a distant descendant it is still reported one level up at a time).
contextgetContext()exposes contextual information for the actor and the current message, such as:- factory methods to create child actors (
actorOf) - system that the actor belongs to
- parent supervisor
- supervised children
- lifecycle monitoring
- hotswap behavior stack as described in Actor.HotSwap Become/Unbecome
- factory methods to create child actors (
You can import the members in the context to avoid prefixing access with context.
sourceclass FirstActor extends Actor {
import context._
val myActor = actorOf(Props[MyActor](), name = "myactor")
def receive = {
case x => myActor ! x
}
}The remaining visible methods are user-overridable life-cycle hooks which are described in the following:
- Scala
-
source
def preStart(): Unit = () def postStop(): Unit = () def preRestart(@nowarn("msg=never used") reason: Throwable, @nowarn("msg=never used") message: Option[Any]): Unit = { context.children.foreach { child => context.unwatch(child) context.stop(child) } postStop() } def postRestart(@nowarn("msg=never used") reason: Throwable): Unit = { preStart() } - Java
-
source
public void preStart() {} public void preRestart(Throwable reason, Optional<Object> message) { for (ActorRef each : getContext().getChildren()) { getContext().unwatch(each); getContext().stop(each); } postStop(); } public void postRestart(Throwable reason) { preStart(); } public void postStop() {}
The implementations shown above are the defaults provided by the Actor trait. AbstractActor class.
Actor Lifecycle
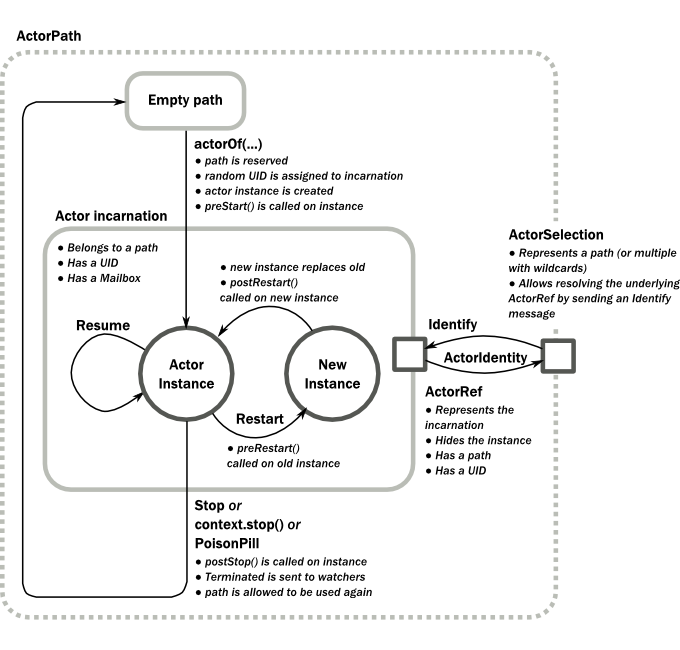
A path in an actor system represents a “place” that might be occupied by a living actor. Initially (apart from system initialized actors) a path is empty. When actorOf() is called it assigns an incarnation of the actor described by the passed PropsProps to the given path. An actor incarnation is identified by the path and a UID.
It is worth noting about the difference between:
- restart
- stop, followed by a re-creation of the actor
as explained below.
A restart only swaps the ActorActor instance defined by the PropsProps but the incarnation and hence the UID remains the same. As long as the incarnation is the same, you can keep using the same ActorRefActorRef. Restart is handled by the Supervision Strategy of actor’s parent actor, and there is more discussion about what restart means.
The lifecycle of an incarnation ends when the actor is stopped. At that point, the appropriate lifecycle events are called and watching actors are notified of the termination. After the incarnation is stopped, the path can be reused again by creating an actor with actorOf(). In this case, the name of the new incarnation will be the same as the previous one, but the UIDs will differ. An actor can be stopped by the actor itself, another actor or the ActorSystemActorSystem (see Stopping actors).
It is important to note that Actors do not stop automatically when no longer referenced, every Actor that is created must also explicitly be destroyed. The only simplification is that stopping a parent Actor will also recursively stop all the child Actors that this parent has created.
An ActorRefActorRef always represents an incarnation (path and UID) not just a given path. Therefore, if an actor is stopped, and a new one with the same name is created then an ActorRef of the old incarnation will not point to the new one.
ActorSelectionActorSelection on the other hand points to the path (or multiple paths if wildcards are used) and is completely oblivious to which incarnation is currently occupying it. ActorSelection cannot be watched for this reason. It is possible to resolve the current incarnation’s ActorRef living under the path by sending an IdentifyIdentify message to the ActorSelection which will be replied to with an ActorIdentityActorIdentity containing the correct reference (see ActorSelection). This can also be done with the resolveOneresolveOne method of the ActorSelection, which returns a FutureCompletionStage of the matching ActorRef.
Lifecycle Monitoring aka DeathWatch
To be notified when another actor terminates (i.e., stops permanently, not a temporary failure and restart), an actor may register itself for reception of the TerminatedTerminated message dispatched by the other actor upon termination (see Stopping Actors). This service is provided by the DeathWatch component of the actor system.
Registering a monitor is easy:
- Scala
-
source
import akka.actor.{ Actor, Props, Terminated } class WatchActor extends Actor { val child = context.actorOf(Props.empty, "child") context.watch(child) // <-- this is the only call needed for registration var lastSender = context.system.deadLetters def receive = { case "kill" => context.stop(child) lastSender = sender() case Terminated(`child`) => lastSender ! "finished" } } - Java
-
source
import akka.actor.Terminated; static class WatchActor extends AbstractActor { private final ActorRef child = getContext().actorOf(Props.empty(), "target"); private ActorRef lastSender = system.deadLetters(); public WatchActor() { getContext().watch(child); // <-- this is the only call needed for registration } @Override public Receive createReceive() { return receiveBuilder() .matchEquals( "kill", s -> { getContext().stop(child); lastSender = getSender(); }) .match( Terminated.class, t -> t.actor().equals(child), t -> { lastSender.tell("finished", getSelf()); }) .build(); } }
It should be noted that the TerminatedTerminated message is generated independently of the order in which registration and termination occur. In particular, the watching actor will receive a Terminated message even if the watched actor has already been terminated at the time of registration.
Registering multiple times does not necessarily lead to multiple messages being generated, but there is no guarantee that only exactly one such message is received: if termination of the watched actor has generated and queued the message, and another registration is done before this message has been processed, then a second message will be queued because registering for monitoring of an already terminated actor leads to the immediate generation of the Terminated message.
It is also possible to deregister from watching another actor’s liveliness using context.unwatch(target)context.unwatch(target). This works even if the Terminated message has already been enqueued in the mailbox; after calling unwatch no Terminated message for that actor will be processed anymore.
Start Hook
Right after starting the actor, its preStartpreStart method is invoked.
- Scala
-
source
override def preStart(): Unit = { child = context.actorOf(Props[MyActor](), "child") } - Java
-
source
@Override public void preStart() { target = getContext().actorOf(Props.create(MyActor.class, "target")); }
This method is called when the actor is first created. During restarts, it is called by the default implementation of postRestartpostRestart, which means that by overriding that method you can choose whether the initialization code in this method is called only exactly once for this actor or every restart. Initialization code which is part of the actor’s constructor will always be called when an instance of the actor class is created, which happens at every restart.
Restart Hooks
All actors are supervised, i.e., linked to another actor with a fault handling strategy. Actors may be restarted in case an exception is thrown while processing a message (see supervision). This restart involves the hooks mentioned above:
- The old actor is informed by calling
preRestartpreRestartwith the exception which caused the restart, and the message which triggered that exception; the latter may beNoneif the restart was not caused by processing a message, e.g. when a supervisor does not trap the exception and is restarted in turn by its supervisor, or if an actor is restarted due to a sibling’s failure. If the message is available, then that message’s sender is also accessible in the usual way (i.e. by callingsendergetSender()). This method is the best place for cleaning up, preparing hand-over to the fresh actor instance, etc. By default, it stops all children and callspostStoppostStop. - The initial factory from the
actorOfcall is used to produce the fresh instance. - The new actor’s
postRestartmethod is invoked with the exception which caused the restart. By default thepreStartis called, just as in the normal start-up case.
An actor restart replaces only the actual actor object; the contents of the mailbox are unaffected by the restart, so the processing of messages will resume after the postRestart hook returns. The message that triggered the exception will not be received again. Any message sent to an actor while it is being restarted will be queued to its mailbox as usual.
Be aware that the ordering of failure notifications relative to user messages is not deterministic. In particular, a parent might restart its child before it has processed the last messages sent by the child before the failure. See Discussion: Message Ordering for details.
Stop Hook
After stopping an actor, its postStoppostStop hook is called, which may be used e.g. for deregistering this actor from other services. This hook is guaranteed to run after message queuing has been disabled for this actor, i.e. messages sent to a stopped actor will be redirected to the deadLettersdeadLetters of the ActorSystemActorSystem.
Identifying Actors via Actor Selection
As described in Actor References, Paths and Addresses, each actor has a unique logical path, which is obtained by following the chain of actors from child to parent until reaching the root of the actor system, and it has a physical path, which may differ if the supervision chain includes any remote supervisors. These paths are used by the system to look up actors, e.g. when a remote message is received and the recipient is searched, but they are also useful more directly: actors may look up other actors by specifying absolute or relative paths—logical or physical—and receive back an ActorSelectionActorSelection with the result:
- Scala
-
source
// will look up this absolute path context.actorSelection("/user/serviceA/aggregator") // will look up sibling beneath same supervisor context.actorSelection("../joe") - Java
-
source
// will look up this absolute path getContext().actorSelection("/user/serviceA/actor"); // will look up sibling beneath same supervisor getContext().actorSelection("../joe");
It is always preferable to communicate with other Actors using their ActorRef instead of relying upon ActorSelection. Exceptions are
- sending messages using the At-Least-Once Delivery facility
- initiating the first contact with a remote system
In all other cases, ActorRefs can be provided during Actor creation or initialization, passing them from parent to child or introducing Actors by sending their ActorRefs to other Actors within messages.
The supplied path is parsed as a java.net.URI, which means that it is split on / into path elements. If the path starts with /, it is absolute and the look-up starts at the root guardian (which is the parent of "/user"); otherwise it starts at the current actor. If a path element equals .., the look-up will take a step “up” towards the supervisor of the currently traversed actor, otherwise it will step “down” to the named child. It should be noted that the .. in actor paths here always means the logical structure, i.e. the supervisor.
The path elements of an actor selection may contain wildcard patterns allowing for broadcasting of messages to that section:
- Scala
-
source
// will look all children to serviceB with names starting with worker context.actorSelection("/user/serviceB/worker*") // will look up all siblings beneath same supervisor context.actorSelection("../*") - Java
-
source
// will look all children to serviceB with names starting with worker getContext().actorSelection("/user/serviceB/worker*"); // will look up all siblings beneath same supervisor getContext().actorSelection("../*");
Messages can be sent via the ActorSelectionActorSelection and the path of the ActorSelection is looked up when delivering each message. If the selection does not match any actors the message will be dropped.
To acquire an ActorRefActorRef for an ActorSelection you need to send a message to the selection and use the sender getSender()) reference of the reply from the actor. There is a built-in IdentifyIdentify message that all Actors will understand and automatically reply to with an ActorIdentityActorIdentity message containing the ActorRefActorRef. This message is handled specially by the actors which are traversed in the sense that if a concrete name lookup fails (i.e. a non-wildcard path element does not correspond to a live actor) then a negative result is generated. Please note that this does not mean that delivery of that reply is guaranteed, it still is a normal message.
- Scala
-
source
import akka.actor.{ Actor, ActorIdentity, Identify, Props, Terminated } class Follower extends Actor { val identifyId = 1 context.actorSelection("/user/another") ! Identify(identifyId) def receive = { case ActorIdentity(`identifyId`, Some(ref)) => context.watch(ref) context.become(active(ref)) case ActorIdentity(`identifyId`, None) => context.stop(self) } def active(another: ActorRef): Actor.Receive = { case Terminated(`another`) => context.stop(self) } } - Java
-
source
import akka.actor.ActorIdentity; import akka.actor.ActorSelection; import akka.actor.Identify; static class Follower extends AbstractActor { final Integer identifyId = 1; public Follower() { ActorSelection selection = getContext().actorSelection("/user/another"); selection.tell(new Identify(identifyId), getSelf()); } @Override public Receive createReceive() { return receiveBuilder() .match( ActorIdentity.class, id -> id.getActorRef().isPresent(), id -> { ActorRef ref = id.getActorRef().get(); getContext().watch(ref); getContext().become(active(ref)); }) .match( ActorIdentity.class, id -> !id.getActorRef().isPresent(), id -> { getContext().stop(getSelf()); }) .build(); } final AbstractActor.Receive active(final ActorRef another) { return receiveBuilder() .match( Terminated.class, t -> t.actor().equals(another), t -> getContext().stop(getSelf())) .build(); } }
You can also acquire an ActorRef for an ActorSelection with the resolveOneresolveOne method of the ActorSelection. It returns a FutureCompletionStage of the matching ActorRef if such an actor exists. It is completed with failure ActorNotFoundActorNotFound if no such actor exists or the identification didn’t complete within the supplied timeout.
Remote actor addresses may also be looked up, if remoting is enabled:
- Scala
-
source
context.actorSelection("akka://app@otherhost:1234/user/serviceB") - Java
-
source
getContext().actorSelection("akka://app@otherhost:1234/user/serviceB");
An example demonstrating actor look-up is given in Remoting Sample.
Messages and immutability
Messages can be any kind of object but have to be immutable. Scala Akka can’t enforce immutability (yet) so this has to be by convention. Primitives like String, Int, Boolean are always immutable. Apart from these the recommended approach is to use Scala case classes that are immutable (if you don’t explicitly expose the state) and works great with pattern matching at the receiver side.
Here is an example: example of an immutable message:
- Scala
-
source
case class User(name: String) // define the case class case class Register(user: User) val user = User("Mike") // create a new case class message val message = Register(user) - Java
-
source
public class ImmutableMessage { private final int sequenceNumber; private final List<String> values; public ImmutableMessage(int sequenceNumber, List<String> values) { this.sequenceNumber = sequenceNumber; this.values = Collections.unmodifiableList(new ArrayList<String>(values)); } public int getSequenceNumber() { return sequenceNumber; } public List<String> getValues() { return values; } }
Send messages
Messages are sent to an Actor through one of the following methods.
!tellmeans “fire-and-forget”, e.g. send a message asynchronously and return immediately. Also known astell.?asksends a message asynchronously and returns aFutureCompletionStagerepresenting a possible reply. Also known asask.
Message ordering is guaranteed on a per-sender basis.
There are performance implications of using ask since something needs to keep track of when it times out, there needs to be something that bridges a Promise into an ActorRefActorRef and it also needs to be reachable through remoting. So always prefer tell for performance, and only ask if you must.
In all these methods you have the option of passing along your own ActorRefActorRef. Make it a practice of doing so because it will allow the receiver actors to be able to respond to your message since the sender reference is sent along with the message.
Tell: Fire-forget
This is the preferred way of sending messages. No blocking waiting for a message. This gives the best concurrency and scalability characteristics.
- Scala
-
source
actorRef ! message - Java
-
source
// don’t forget to think about who is the sender (2nd argument) target.tell(message, getSelf());
If invoked from within an Actor, then the sending actor reference will be implicitly passed along with the message and available to the receiving Actor in its sender(): ActorRef member method. The target actor can use this to reply to the original sender, by using sender() ! replyMsg.
If invoked from an instance that is not an Actor the sender will be deadLetters actor reference by default.
The sender reference is passed along with the message and available within the receiving actor via its getSender() method while processing this message. Inside of an actor it is usually getSelf() who shall be the sender, but there can be cases where replies shall be routed to some other actor—e.g. the parent—in which the second argument to tell would be a different one. Outside of an actor and if no reply is needed the second argument can be null; if a reply is needed outside of an actor you can use the ask-pattern described next.
Ask: Send-And-Receive-Future
The ask pattern involves actors as well as futures, hence it is offered as a use pattern rather than a method on ActorRefActorRef:
- Scala
-
source
import akka.pattern.{ ask, pipe } import system.dispatcher // The ExecutionContext that will be used final case class Result(x: Int, s: String, d: Double) case object Request implicit val timeout: Timeout = 5.seconds // needed for `?` below val f: Future[Result] = for { x <- ask(actorA, Request).mapTo[Int] // call pattern directly s <- actorB.ask(Request).mapTo[String] // call by implicit conversion d <- (actorC ? Request).mapTo[Double] // call by symbolic name } yield Result(x, s, d) f.pipeTo(actorD) // .. or .. pipe(f) to actorD - Java
-
source
import static akka.pattern.Patterns.ask; import static akka.pattern.Patterns.pipe; import java.util.concurrent.CompletableFuture; final Duration t = Duration.ofSeconds(5); // using 1000ms timeout CompletableFuture<Object> future1 = ask(actorA, "request", Duration.ofMillis(1000)).toCompletableFuture(); // using timeout from above CompletableFuture<Object> future2 = ask(actorB, "another request", t).toCompletableFuture(); CompletableFuture<Result> transformed = future1.thenCombine(future2, (x, s) -> new Result((String) x, (String) s)); pipe(transformed, system.dispatcher()).to(actorC);
This example demonstrates ask together with the pipeTopipeTo pattern on futures, because this is likely to be a common combination. Please note that all of the above is completely non-blocking and asynchronous: ask produces a FutureCompletionStage, three two of which are composed into a new future using the for-comprehension and then pipeTo installs an onComplete-handler on the Future to affect CompletableFuture.allOf and thenApply methods and then pipe installs a handler on the CompletionStage to effect the submission of the aggregated Result to another actor.
Using ask will send a message to the receiving Actor as with tell, and the receiving actor must reply with sender() ! reply getSender().tell(reply, getSelf()) in order to complete the returned FutureCompletionStage with a value. The ask operation involves creating an internal actor for handling this reply, which needs to have a timeout after which it is destroyed in order not to leak resources; see more below.
To complete the FutureCompletionStage with an exception you need to send an FailureFailure message to the sender. This is not done automatically when an actor throws an exception while processing a message.
Please note that Scala’s Try sub types scala.util.Failure and scala.util.Success are not treated especially, and would complete the ask FutureCompletionStage with the given value - only the akka.actor.Status messages are treated specially by the ask pattern.
- Scala
-
source
try { val result = operation() sender() ! result } catch { case e: Exception => sender() ! akka.actor.Status.Failure(e) throw e } - Java
-
source
try { String result = operation(); getSender().tell(result, getSelf()); } catch (Exception e) { getSender().tell(new akka.actor.Status.Failure(e), getSelf()); throw e; }
If the actor does not complete the FutureCompletionStage, it will expire after the timeout period, completing it with an AskTimeoutException. The timeout is taken from one of the following locations in order of precedence: specified as parameter to the ask method; this will complete the CompletionStage with an AskTimeoutException.
-
explicitly given timeout as in:
source
import scala.concurrent.duration._ import akka.pattern.ask val future = myActor.ask("hello")(5 seconds) -
implicit argument of type
akka.util.Timeout, e.g.source
import scala.concurrent.duration._ import akka.util.Timeout import akka.pattern.ask implicit val timeout: Timeout = 5.seconds val future = myActor ? "hello"
The onComplete method of the FuturethenRun method of the CompletionStage can be used to register a callback to get a notification when the FutureCompletionStage completes, giving you a way to avoid blocking.
When using future callbacks, such as onComplete, or mapsuch as thenRun, or thenApply inside actors you need to carefully avoid closing over the containing actor’s reference, i.e. do not call methods or access mutable state on the enclosing actor from within the callback. This would break the actor encapsulation and may introduce synchronization bugs and race conditions because the callback will be scheduled concurrently to the enclosing actor. Unfortunately, there is not yet a way to detect these illegal accesses at compile time. See also: Actors and shared mutable state
Forward message
You can forward a message from one actor to another. This means that the original sender address/reference is maintained even though the message is going through a ‘mediator’. This can be useful when writing actors that work as routers, load-balancers, replicators etc.
Receive messages
An Actor has to implement the receive method to receive messages: define its initial receive behavior by implementing the createReceive method in the AbstractActor:
- Scala
-
source
type Receive = PartialFunction[Any, Unit] def receive: Actor.Receive - Java
-
source
@Override public Receive createReceive() { return receiveBuilder().match(String.class, s -> System.out.println(s.toLowerCase())).build(); }
This method returns a PartialFunction, e.g. a ‘match/case’ clause in which the message can be matched against the different case clauses using Scala pattern matching. Here is an example:
The return type is AbstractActor.Receive that defines which messages your Actor can handle, along with the implementation of how the messages should be processed. You can build such behavior with a builder named receiveBuilder. Here is an example:
- Scala
-
source
import akka.actor.Actor import akka.actor.Props import akka.event.Logging class MyActor extends Actor { val log = Logging(context.system, this) def receive = { case "test" => log.info("received test") case _ => log.info("received unknown message") } } - Java
-
source
import akka.actor.AbstractActor; import akka.event.Logging; import akka.event.LoggingAdapter; public class MyActor extends AbstractActor { private final LoggingAdapter log = Logging.getLogger(getContext().getSystem(), this); @Override public Receive createReceive() { return receiveBuilder() .match( String.class, s -> { log.info("Received String message: {}", s); }) .matchAny(o -> log.info("received unknown message")) .build(); } }
In case you want to provide many match cases but want to avoid creating a long call trail, you can split the creation of the builder into multiple statements as in the example:
sourceimport akka.actor.AbstractActor;
import akka.event.Logging;
import akka.event.LoggingAdapter;
import akka.japi.pf.ReceiveBuilder;
public class GraduallyBuiltActor extends AbstractActor {
private final LoggingAdapter log = Logging.getLogger(getContext().getSystem(), this);
@Override
public Receive createReceive() {
ReceiveBuilder builder = ReceiveBuilder.create();
builder.match(
String.class,
s -> {
log.info("Received String message: {}", s);
});
// do some other stuff in between
builder.matchAny(o -> log.info("received unknown message"));
return builder.build();
}
}
Using small methods is a good practice, also in actors. It’s recommended to delegate the actual work of the message processing to methods instead of defining a huge ReceiveBuilder with lots of code in each lambda. A well-structured actor can look like this:
sourcestatic class WellStructuredActor extends AbstractActor {
public static class Msg1 {}
public static class Msg2 {}
public static class Msg3 {}
@Override
public Receive createReceive() {
return receiveBuilder()
.match(Msg1.class, this::receiveMsg1)
.match(Msg2.class, this::receiveMsg2)
.match(Msg3.class, this::receiveMsg3)
.build();
}
private void receiveMsg1(Msg1 msg) {
// actual work
}
private void receiveMsg2(Msg2 msg) {
// actual work
}
private void receiveMsg3(Msg3 msg) {
// actual work
}
}
That has benefits such as:
- easier to see what kind of messages the actor can handle
- readable stack traces in case of exceptions
- works better with performance profiling tools
- Java HotSpot has a better opportunity for making optimizations
The Receive can be implemented in other ways than using the ReceiveBuilder since in the end, it is just a wrapper around a Scala PartialFunction. In Java, you can implement PartialFunction by extending AbstractPartialFunction.
If the validation of the ReceiveBuilder match logic turns out to be a bottleneck for some of your actors you can consider implementing it at a lower level by extending UntypedAbstractActor instead of AbstractActor. The partial functions created by the ReceiveBuilder consist of multiple lambda expressions for every match statement, where each lambda is referencing the code to be run. This is something that the JVM can have problems optimizing and the resulting code might not be as performant as the untyped version. When extending UntypedAbstractActor each message is received as an untyped Object and you have to inspect and cast it to the actual message type in other ways, like this:
sourcestatic class OptimizedActor extends UntypedAbstractActor {
public static class Msg1 {}
public static class Msg2 {}
public static class Msg3 {}
@Override
public void onReceive(Object msg) throws Exception {
if (msg instanceof Msg1) receiveMsg1((Msg1) msg);
else if (msg instanceof Msg2) receiveMsg2((Msg2) msg);
else if (msg instanceof Msg3) receiveMsg3((Msg3) msg);
else unhandled(msg);
}
private void receiveMsg1(Msg1 msg) {
// actual work
}
private void receiveMsg2(Msg2 msg) {
// actual work
}
private void receiveMsg3(Msg3 msg) {
// actual work
}
}Reply to messages
If you want to have a handle for replying to a message, you can use sender getSender(), which gives you an ActorRef. You can reply by sending to that ActorRef with sender() ! replyMsg. getSender().tell(replyMsg, getSelf()). You can also store the ActorRef for replying later, or passing it on to other actors. If there is no sender (a message was sent without an actor or future context) then the sender defaults to a ‘dead-letter’ actor ref.
- Scala
-
source
sender() ! x // replies will go to this actor - Java
-
source
getSender().tell(s, getSelf());
Receive timeout
The ActorContext.setReceiveTimeoutActorContext.setReceiveTimeout defines the inactivity timeout after which the sending of a ReceiveTimeoutReceiveTimeout message is triggered. When specified, the receive function should be able to handle an akka.actor.ReceiveTimeout message. 1 millisecond is the minimum supported timeout.
Please note that the receive timeout might fire and enqueue the ReceiveTimeout message right after another message was enqueued; hence it is not guaranteed that upon reception of the receive timeout there must have been an idle period beforehand as configured via this method.
Once set, the receive timeout stays in effect (i.e. continues firing repeatedly after inactivity periods).
To cancel the sending of receive timeout notifications, use cancelReceiveTimeout.
- Scala
-
source
import akka.actor.ReceiveTimeout import scala.concurrent.duration._ class MyActor extends Actor { // To set an initial delay context.setReceiveTimeout(30 milliseconds) def receive = { case "Hello" => // To set in a response to a message context.setReceiveTimeout(100 milliseconds) case ReceiveTimeout => // To turn it off context.setReceiveTimeout(Duration.Undefined) throw new RuntimeException("Receive timed out") } } - Java
-
source
static class ReceiveTimeoutActor extends AbstractActor { public ReceiveTimeoutActor() { // To set an initial delay getContext().setReceiveTimeout(Duration.ofSeconds(10)); } @Override public Receive createReceive() { return receiveBuilder() .matchEquals( "Hello", s -> { // To set in a response to a message getContext().setReceiveTimeout(Duration.ofSeconds(1)); }) .match( ReceiveTimeout.class, r -> { // To turn it off getContext().cancelReceiveTimeout(); }) .build(); } }
Messages marked with NotInfluenceReceiveTimeoutNotInfluenceReceiveTimeout will not reset the timer. This can be useful when ReceiveTimeoutReceiveTimeout should be fired by external inactivity but not influenced by internal activity, e.g. scheduled tick messages.
Timers, scheduled messages
Messages can be scheduled to be sent at a later point by using the Scheduler directly, but when scheduling periodic or single messages in an actor to itself it’s more convenient and safe to use the support for named timers. The lifecycle of scheduled messages can be difficult to manage when the actor is restarted and that is taken care of by the timers.
- Scala
-
source
import scala.concurrent.duration._ import akka.actor.Actor import akka.actor.Timers object MyActor { private case object TickKey private case object FirstTick private case object Tick } class MyActor extends Actor with Timers { import MyActor._ timers.startSingleTimer(TickKey, FirstTick, 500.millis) def receive = { case FirstTick => // do something useful here timers.startTimerWithFixedDelay(TickKey, Tick, 1.second) case Tick => // do something useful here } } - Java
-
source
import akka.actor.AbstractActorWithTimers; import java.time.Duration; static class MyActor extends AbstractActorWithTimers { private static Object TICK_KEY = "TickKey"; private static final class FirstTick {} private static final class Tick {} public MyActor() { getTimers().startSingleTimer(TICK_KEY, new FirstTick(), Duration.ofMillis(500)); } @Override public Receive createReceive() { return receiveBuilder() .match( FirstTick.class, message -> { // do something useful here getTimers().startTimerWithFixedDelay(TICK_KEY, new Tick(), Duration.ofSeconds(1)); }) .match( Tick.class, message -> { // do something useful here }) .build(); } }
The Scheduler documentation describes the difference between fixed-delay and fixed-rate scheduling. If you are uncertain of which one to use you should pick startTimerWithFixedDelaystartTimerWithFixedDelay.
Each timer has a key and can be replaced or cancelled. It’s guaranteed that a message from the previous incarnation of the timer with the same key is not received, even though it might already be enqueued in the mailbox when it was cancelled or the new timer was started.
The timers are bound to the lifecycle of the actor that owns it and thus are cancelled automatically when it is restarted or stopped. Note that the TimerSchedulerTimerScheduler is not thread-safe, i.e. it must only be used within the actor that owns it.
Stopping actors
Actors are stopped by invoking the stop method of a ActorRefFactoryActorRefFactory, i.e. ActorContextActorContext or ActorSystemActorSystem. Typically the context is used for stopping the actor itself or child actors and the system for stopping top-level actors. The actual termination of the actor is performed asynchronously, i.e. stop may return before the actor is stopped.
- Scala
-
source
class MyActor extends Actor { val child: ActorRef = ??? def receive = { case "interrupt-child" => context.stop(child) case "done" => context.stop(self) } } - Java
-
source
import akka.actor.AbstractActor; import akka.actor.ActorRef; public class MyStoppingActor extends AbstractActor { ActorRef child = null; // ... creation of child ... @Override public Receive createReceive() { return receiveBuilder() .matchEquals("interrupt-child", m -> getContext().stop(child)) .matchEquals("done", m -> getContext().stop(getSelf())) .build(); } }
Processing of the current message, if any, will continue before the actor is stopped, but additional messages in the mailbox will not be processed. By default, these messages are sent to the deadLettersdeadLetters of the ActorSystem, but that depends on the mailbox implementation.
Termination of an actor proceeds in two steps: first the actor suspends its mailbox processing and sends a stop command to all its children, then it keeps processing the internal termination notifications from its children until the last one is gone, finally terminating itself (invoking postStoppostStop, dumping mailbox, publishing TerminatedTerminated on the DeathWatch, telling its supervisor). This procedure ensures that actor system sub-trees terminate in an orderly fashion, propagating the stop command to the leaves and collecting their confirmation back to the stopped supervisor. If one of the actors do not respond (i.e. processing a message for extended periods of time and therefore not receiving the stop command), this whole process will be stuck.
Upon ActorSystem.terminate()ActorSystem.terminate(), the system guardian actors will be stopped, and the aforementioned process will ensure proper termination of the whole system. See Coordinated Shutdown.
The postStop() hook is invoked after an actor is fully stopped. This enables cleaning up of resources:
- Scala
-
source
override def postStop(): Unit = { () } - Java
-
source
@Override public void postStop() { final String message = "stopped"; // don’t forget to think about who is the sender (2nd argument) target.tell(message, getSelf()); final Object result = ""; target.forward(result, getContext()); target = null; }
Since stopping an actor is asynchronous, you cannot immediately reuse the name of the child you just stopped; this will result in an InvalidActorNameExceptionInvalidActorNameException. Instead, watch() the terminating actor and create its replacement in response to the TerminatedTerminated message which will eventually arrive.
PoisonPill
You can also send an actor the PoisonPillPoisonPill message, which will stop the actor when the message is processed. PoisonPill is enqueued as ordinary messages and will be handled after messages that were already queued in the mailbox.
- Scala
-
source
watch(victim) victim ! PoisonPill - Java
-
source
victim.tell(akka.actor.PoisonPill.getInstance(), ActorRef.noSender());
Killing an Actor
You can also “kill” an actor by sending a KillKill message. Unlike PoisonPill this will cause the actor to throw a ActorKilledExceptionActorKilledException, triggering a failure. The actor will suspend operation and its supervisor will be asked how to handle the failure, which may mean resuming the actor, restarting it or terminating it completely. See What Supervision Means for more information.
Use Kill like this:
- Scala
-
source
context.watch(victim) // watch the Actor to receive Terminated message once it dies victim ! Kill expectMsgPF(hint = "expecting victim to terminate") { case Terminated(v) if v == victim => v // the Actor has indeed terminated } - Java
-
source
victim.tell(akka.actor.Kill.getInstance(), ActorRef.noSender()); // expecting the actor to indeed terminate: expectTerminated(Duration.ofSeconds(3), victim);
In general, it is not recommended to overly rely on either PoisonPill or Kill in designing your actor interactions, as often a protocol-level message like PleaseCleanupAndStop which the actor knows how to handle is encouraged. The messages are there for being able to stop actors over which design you do not have control over.
Graceful Stop
gracefulStopgracefulStop is useful if you need to wait for termination or compose ordered termination of several actors:
- Scala
-
source
import akka.pattern.gracefulStop import scala.concurrent.Await try { val stopped: Future[Boolean] = gracefulStop(actorRef, 5 seconds, Manager.Shutdown) Await.result(stopped, 6 seconds) // the actor has been stopped } catch { // the actor wasn't stopped within 5 seconds case e: akka.pattern.AskTimeoutException => } - Java
-
source
import static akka.pattern.Patterns.gracefulStop; import akka.pattern.AskTimeoutException; import java.util.concurrent.CompletionStage; try { CompletionStage<Boolean> stopped = gracefulStop(actorRef, Duration.ofSeconds(5), Manager.SHUTDOWN); stopped.toCompletableFuture().get(6, TimeUnit.SECONDS); // the actor has been stopped } catch (AskTimeoutException e) { // the actor wasn't stopped within 5 seconds }
When gracefulStop() returns successfully, the actor’s postStoppostStop hook will have been executed: there exists a happens-before edge between the end of postStop() and the return of gracefulStop().
In the above example, a custom Manager.Shutdown message is sent to the target actor to initiate the process of stopping the actor. You can use PoisonPill for this, but then you have limited possibilities to perform interactions with other actors before stopping the target actor. Simple cleanup tasks can be handled in postStop.
Keep in mind that an actor stopping and its name being deregistered are separate events that happen asynchronously from each other. Therefore it may be that you will find the name still in use after gracefulStop() returned. To guarantee proper deregistration, only reuse names from within a supervisor you control and only in response to a TerminatedTerminated message, i.e. not for top-level actors.
Become/Unbecome
Upgrade
Akka supports hotswapping the Actor’s message loop (e.g. its implementation) at runtime: invoke the context.becomecontext.become method from within the Actor. become takes a PartialFunction[Any, Unit] PartialFunction<Object, BoxedUnit> that implements the new message handler. The hotswapped code is kept in a Stack that can be pushed and popped.
Please note that the actor will revert to its original behavior when restarted by its Supervisor.
To hotswap the Actor behavior using become:
- Scala
-
source
class HotSwapActor extends Actor { import context._ def angry: Receive = { case "foo" => sender() ! "I am already angry?" case "bar" => become(happy) } def happy: Receive = { case "bar" => sender() ! "I am already happy :-)" case "foo" => become(angry) } def receive = { case "foo" => become(angry) case "bar" => become(happy) } } - Java
-
source
static class HotSwapActor extends AbstractActor { private AbstractActor.Receive angry; private AbstractActor.Receive happy; public HotSwapActor() { angry = receiveBuilder() .matchEquals( "foo", s -> { getSender().tell("I am already angry?", getSelf()); }) .matchEquals( "bar", s -> { getContext().become(happy); }) .build(); happy = receiveBuilder() .matchEquals( "bar", s -> { getSender().tell("I am already happy :-)", getSelf()); }) .matchEquals( "foo", s -> { getContext().become(angry); }) .build(); } @Override public Receive createReceive() { return receiveBuilder() .matchEquals("foo", s -> getContext().become(angry)) .matchEquals("bar", s -> getContext().become(happy)) .build(); } }
This variant of the become method is useful for many different things, such as to implement a Finite State Machine (FSM). It will replace the current behavior (i.e. the top of the behavior stack), which means that you do not use unbecomeunbecome, instead always the next behavior is explicitly installed.
The other way of using become does not replace but add to the top of the behavior stack. In this case, care must be taken to ensure that the number of “pop” operations (i.e. unbecome) matches the number of “push” ones in the long run, otherwise this amounts to a memory leak (which is why this behavior is not the default).
- Scala
-
source
case object Swap class Swapper extends Actor { import context._ val log = Logging(system, this) def receive = { case Swap => log.info("Hi") become({ case Swap => log.info("Ho") unbecome() // resets the latest 'become' (just for fun) }, discardOld = false) // push on top instead of replace } } object SwapperApp extends App { val system = ActorSystem("SwapperSystem") val swap = system.actorOf(Props[Swapper](), name = "swapper") swap ! Swap // logs Hi swap ! Swap // logs Ho swap ! Swap // logs Hi swap ! Swap // logs Ho swap ! Swap // logs Hi swap ! Swap // logs Ho } - Java
-
source
static class Swapper extends AbstractLoggingActor { @Override public Receive createReceive() { return receiveBuilder() .matchEquals( Swap, s -> { log().info("Hi"); getContext() .become( receiveBuilder() .matchEquals( Swap, x -> { log().info("Ho"); getContext() .unbecome(); // resets the latest 'become' (just for fun) }) .build(), false); // push on top instead of replace }) .build(); } } static class SwapperApp { public static void main(String[] args) { ActorSystem system = ActorSystem.create("SwapperSystem"); ActorRef swapper = system.actorOf(Props.create(Swapper.class), "swapper"); swapper.tell(Swap, ActorRef.noSender()); // logs Hi swapper.tell(Swap, ActorRef.noSender()); // logs Ho swapper.tell(Swap, ActorRef.noSender()); // logs Hi swapper.tell(Swap, ActorRef.noSender()); // logs Ho swapper.tell(Swap, ActorRef.noSender()); // logs Hi swapper.tell(Swap, ActorRef.noSender()); // logs Ho system.terminate(); } }
Encoding Scala Actors nested receives without accidentally leaking memory
See this Unnested receive example.
Stash
The Stash trait AbstractActorWithStash class enables an actor to temporarily stash away messages that can not or should not be handled using the actor’s current behavior. Upon changing the actor’s message handler, i.e., right before invoking context.become or context.unbecome getContext().become() or getContext().unbecome(), all stashed messages can be “unstashed”, thereby prepending them to the actor’s mailbox. This way, the stashed messages can be processed in the same order as they have been received originally. An actor that extends AbstractActorWithStash will automatically get a deque-based mailbox.
The trait Stash extends the marker trait RequiresMessageQueue[DequeBasedMessageQueueSemantics] which requests the system to automatically choose a deque based mailbox implementation for the actor. If you want more control over the mailbox, see the documentation on mailboxes: Mailboxes.
The abstract class AbstractActorWithStash implements the marker interface RequiresMessageQueue<DequeBasedMessageQueueSemantics> which requests the system to automatically choose a deque based mailbox implementation for the actor. If you want more control over the mailbox, see the documentation on mailboxes: Mailboxes.
Here is an example of the Stash trait AbstractActorWithStash class in action:
- Scala
-
source
import akka.actor.Stash class ActorWithProtocol extends Actor with Stash { def receive = { case "open" => unstashAll() context.become({ case "write" => // do writing... case "close" => unstashAll() context.unbecome() case msg => stash() }, discardOld = false) // stack on top instead of replacing case msg => stash() } } - Java
-
source
static class ActorWithProtocol extends AbstractActorWithStash { @Override public Receive createReceive() { return receiveBuilder() .matchEquals( "open", s -> { getContext() .become( receiveBuilder() .matchEquals( "write", ws -> { /* do writing */ }) .matchEquals( "close", cs -> { unstashAll(); getContext().unbecome(); }) .matchAny(msg -> stash()) .build(), false); }) .matchAny(msg -> stash()) .build(); } }
Invoking stash() adds the current message (the message that the actor received last) to the actor’s stash. It is typically invoked when handling the default case in the actor’s message handler to stash messages that aren’t handled by the other cases. It is illegal to stash the same message twice; to do so results in an IllegalStateException being thrown. The stash may also be bounded in which case invoking stash() may lead to a capacity violation, which results in a StashOverflowExceptionStashOverflowException. The capacity of the stash can be configured using the stash-capacity setting (an Int) of the mailbox’s configuration.
Invoking unstashAll() enqueues messages from the stash to the actor’s mailbox until the capacity of the mailbox (if any) has been reached (note that messages from the stash are prepended to the mailbox). In case a bounded mailbox overflows, a MessageQueueAppendFailedException is thrown. The stash is guaranteed to be empty after calling unstashAll().
The stash is backed by a scala.collection.immutable.Vector. As a result, even a very large number of messages may be stashed without a major impact on performance.
Note that the Stash trait must be mixed into (a subclass of) the Actor trait before any trait/class that overrides the preRestart] callback. This means it’s not possible to write Actor with MyActor with Stash if MyActor overrides preRestart.
Note that the stash is part of the ephemeral actor state, unlike the mailbox. Therefore, it should be managed like other parts of the actor’s state which have the same property.
However, the Stash trait AbstractActorWithStash class implementation of preRestart will call unstashAll(). This means that before the actor restarts, it will transfer all stashed messages back to the actor’s mailbox.
The result of this is that when an actor is restarted, any stashed messages will be delivered to the new incarnation of the actor. This is usually the desired behavior.
If you want to enforce that your actor can only work with an unbounded stash, then you should use the UnboundedStash trait AbstractActorWithUnboundedStash class instead.
Extending Actors using PartialFunction chaining
Sometimes it can be useful to share common behavior among a few actors, or compose one actor’s behavior from multiple smaller functions. This is possible because an actor’s receivecreateReceive method returns an Actor.Receive, which is a type alias for PartialFunction[Any,Unit], and partial functions can be chained together using the PartialFunction#orElse method. You can chain as many functions as you need, however you should keep in mind that “first match” wins - which may be important when combining functions that both can handle the same type of message.
For example, imagine you have a set of actors which are either Producers or Consumers, yet sometimes it makes sense to have an actor share both behaviors. This can be achieved without having to duplicate code by extracting the behaviors to traits and implementing the actor’s receive as a combination of these partial functions.
source
trait ProducerBehavior {
this: Actor =>
val producerBehavior: Receive = {
case GiveMeThings =>
sender() ! Give("thing")
}
}
trait ConsumerBehavior {
this: Actor with ActorLogging =>
val consumerBehavior: Receive = {
case ref: ActorRef =>
ref ! GiveMeThings
case Give(thing) =>
log.info("Got a thing! It's {}", thing)
}
}
class Producer extends Actor with ProducerBehavior {
def receive = producerBehavior
}
class Consumer extends Actor with ActorLogging with ConsumerBehavior {
def receive = consumerBehavior
}
class ProducerConsumer extends Actor with ActorLogging with ProducerBehavior with ConsumerBehavior {
def receive = producerBehavior.orElse[Any, Unit](consumerBehavior)
}
// protocol
case object GiveMeThings
final case class Give(thing: Any)
Instead of inheritance the same pattern can be applied via composition - compose the receive method using partial functions from delegates.
Initialization patterns
The rich lifecycle hooks of Actors provide a useful toolkit to implement various initialization patterns. During the lifetime of an ActorRefActorRef, an actor can potentially go through several restarts, where the old instance is replaced by a fresh one, invisibly to the outside observer who only sees the ActorRef.
Initialization might be necessary every time an actor is instantiated, but sometimes one needs initialization to happen only at the birth of the first instance when the ActorRef is created. The following sections provide patterns for different initialization needs.
Initialization via constructor
Using the constructor for initialization has various benefits. First of all, it makes it possible to use val fields to store any state that does not change during the life of the actor instance, making the implementation of the actor more robust. The constructor is invoked when an actor instance is created calling actorOf and also on restart, therefore the internals of the actor can always assume that proper initialization happened. This is also the drawback of this approach, as there are cases when one would like to avoid reinitializing internals on restart. For example, it is often useful to preserve child actors across restarts. The following section provides a pattern for this case.
Initialization via preStart
The method preStartpreStart of an actor is only called once directly during the initialization of the first instance, that is, at the creation of its ActorRef. In the case of restarts, preStart() is called from postRestartpostRestart, therefore if not overridden, preStart() is called on every restart. However, by overriding postRestart() one can disable this behavior, and ensure that there is only one call to preStart().
One useful usage of this pattern is to disable creation of new ActorRefs for children during restarts. This can be achieved by overriding preRestartpreRestart. Below is the default implementation of these lifecycle hooks:
- Scala
-
source
override def preStart(): Unit = { // Initialize children here } // Overriding postRestart to disable the call to preStart() // after restarts override def postRestart(reason: Throwable): Unit = () // The default implementation of preRestart() stops all the children // of the actor. To opt-out from stopping the children, we // have to override preRestart() override def preRestart(reason: Throwable, message: Option[Any]): Unit = { // Keep the call to postStop(), but no stopping of children postStop() } - Java
-
source
@Override public void preStart() { // Initialize children here } // Overriding postRestart to disable the call to preStart() // after restarts @Override public void postRestart(Throwable reason) {} // The default implementation of preRestart() stops all the children // of the actor. To opt-out from stopping the children, we // have to override preRestart() @Override public void preRestart(Throwable reason, Optional<Object> message) throws Exception { // Keep the call to postStop(), but no stopping of children postStop(); }
Please note, that the child actors are still restarted, but no new ActorRefActorRef is created. One can recursively apply the same principles for the children, ensuring that their preStart() method is called only at the creation of their refs.
For more information see What Restarting Means.
Initialization via message passing
There are cases when it is impossible to pass all the information needed for actor initialization in the constructor, for example in the presence of circular dependencies. In this case, the actor should listen for an initialization message, and use become()become() or a finite state-machine state transition to encode the initialized and uninitialized states of the actor.
- Scala
-
source
var initializeMe: Option[String] = None override def receive = { case "init" => initializeMe = Some("Up and running") context.become(initialized, discardOld = true) } def initialized: Receive = { case "U OK?" => initializeMe.foreach { sender() ! _ } } - Java
-
source
@Override public Receive createReceive() { return receiveBuilder() .matchEquals( "init", m1 -> { initializeMe = "Up and running"; getContext() .become( receiveBuilder() .matchEquals( "U OK?", m2 -> { getSender().tell(initializeMe, getSelf()); }) .build()); }) .build(); }
If the actor may receive messages before it has been initialized, a useful tool can be the Stash to save messages until the initialization finishes, and replaying them after the actor became initialized.
This pattern should be used with care, and applied only when none of the patterns above are applicable. One of the potential issues is that messages might be lost when sent to remote actors. Also, publishing an ActorRefActorRef in an uninitialized state might lead to the condition that it receives a user message before the initialization has been done.