Cluster Usage (Scala)
Note
This module is experimental. This document describes how to use the features implemented so far. More features are coming in Akka Coltrane. Track progress of the Coltrane milestone in Assembla and the Roadmap.
For introduction to the Akka Cluster concepts please see Cluster Specification.
Preparing Your Project for Clustering
The Akka cluster is a separate jar file. Make sure that you have the following dependency in your project:
"com.typesafe.akka" %% "akka-cluster-experimental" % "2.1.4"
If you are using the latest nightly build you should pick a timestamped Akka version from http://repo.typesafe.com/typesafe/snapshots/com/typesafe/akka/akka-cluster-experimental_2.10/. We recommend against using SNAPSHOT in order to obtain stable builds.
A Simple Cluster Example
The following small program together with its configuration starts an ActorSystem with the Cluster enabled. It joins the cluster and logs some membership events.
Try it out:
- Add the following application.conf in your project, place it in src/main/resources:
akka {
actor {
provider = "akka.cluster.ClusterActorRefProvider"
}
remote {
transport = "akka.remote.netty.NettyRemoteTransport"
log-remote-lifecycle-events = off
netty {
hostname = "127.0.0.1"
port = 0
}
}
cluster {
seed-nodes = [
"akka://[email protected]:2551",
"akka://[email protected]:2552"]
auto-down = on
}
}
To enable cluster capabilities in your Akka project you should, at a minimum, add the Remoting (Scala) settings, but with akka.cluster.ClusterActorRefProvider. The akka.cluster.seed-nodes should normally also be added to your application.conf file.
The seed nodes are configured contact points for initial, automatic, join of the cluster.
Note that if you are going to start the nodes on different machines you need to specify the ip-addresses or host names of the machines in application.conf instead of 127.0.0.1
- Add the following main program to your project, place it in src/main/scala:
package sample.cluster.simple
import akka.actor._
import akka.cluster.Cluster
import akka.cluster.ClusterEvent._
object SimpleClusterApp {
def main(args: Array[String]): Unit = {
// Override the configuration of the port
// when specified as program argument
if (args.nonEmpty) System.setProperty("akka.remote.netty.port", args(0))
// Create an Akka system
val system = ActorSystem("ClusterSystem")
val clusterListener = system.actorOf(Props(new Actor with ActorLogging {
def receive = {
case state: CurrentClusterState ⇒
log.info("Current members: {}", state.members)
case MemberJoined(member) ⇒
log.info("Member joined: {}", member)
case MemberUp(member) ⇒
log.info("Member is Up: {}", member)
case UnreachableMember(member) ⇒
log.info("Member detected as unreachable: {}", member)
case _: ClusterDomainEvent ⇒ // ignore
}
}), name = "clusterListener")
Cluster(system).subscribe(clusterListener, classOf[ClusterDomainEvent])
}
}
Start the first seed node. Open a sbt session in one terminal window and run:
run-main sample.cluster.simple.SimpleClusterApp 2551
2551 corresponds to the port of the first seed-nodes element in the configuration. In the log output you see that the cluster node has been started and changed status to 'Up'.
Start the second seed node. Open a sbt session in another terminal window and run:
run-main sample.cluster.simple.SimpleClusterApp 2552
2552 corresponds to the port of the second seed-nodes element in the configuration. In the log output you see that the cluster node has been started and joins the other seed node and becomes a member of the cluster. Its status changed to 'Up'.
Switch over to the first terminal window and see in the log output that the member joined.
Start another node. Open a sbt session in yet another terminal window and run:
run-main sample.cluster.simple.SimpleClusterApp
Now you don't need to specify the port number, and it will use a random available port. It joins one of the configured seed nodes. Look at the log output in the different terminal windows.
Start even more nodes in the same way, if you like.
6. Shut down one of the nodes by pressing 'ctrl-c' in one of the terminal windows. The other nodes will detect the failure after a while, which you can see in the log output in the other terminals.
Look at the source code of the program again. What it does is to create an actor and register it as subscriber of certain cluster events. It gets notified with an snapshot event, CurrentClusterState that holds full state information of the cluster. After that it receives events for changes that happen in the cluster.
Automatic vs. Manual Joining
You may decide if joining to the cluster should be done automatically or manually. By default it is automatic and you need to define the seed nodes in configuration so that a new node has an initial contact point. When a new node is started it sends a message to all seed nodes and then sends join command to the one that answers first. If no one of the seed nodes replied (might not be started yet) it retries this procedure until successful or shutdown.
The seed nodes can be started in any order and it is not necessary to have all seed nodes running, but the node configured as the first element in the seed-nodes configuration list must be started when initially starting a cluster, otherwise the other seed-nodes will not become initialized and no other node can join the cluster. It is quickest to start all configured seed nodes at the same time (order doesn't matter), otherwise it can take up to the configured seed-node-timeout until the nodes can join.
Once more than two seed nodes have been started it is no problem to shut down the first seed node. If the first seed node is restarted it will first try join the other seed nodes in the existing cluster.
You can disable automatic joining with configuration:
akka.cluster.auto-join = off
Then you need to join manually, using JMX or Command Line Management. You can join to any node in the cluster. It doesn't have to be configured as seed node. If you are not using auto-join there is no need to configure seed nodes at all.
Joining can also be performed programatically with Cluster(system).join(address).
Automatic vs. Manual Downing
When a member is considered by the failure detector to be unreachable the leader is not allowed to perform its duties, such as changing status of new joining members to 'Up'. The status of the unreachable member must be changed to 'Down'. This can be performed automatically or manually. By default it must be done manually, using using JMX or Command Line Management.
It can also be performed programatically with Cluster(system).down(address).
You can enable automatic downing with configuration:
akka.cluster.auto-down = on
Be aware of that using auto-down implies that two separate clusters will automatically be formed in case of network partition. That might be desired by some applications but not by others.
Subscribe to Cluster Events
You can subscribe to change notifications of the cluster membership by using Cluster(system).subscribe(subscriber, to). A snapshot of the full state, akka.cluster.ClusterEvent.CurrentClusterState, is sent to the subscriber as the first event, followed by events for incremental updates.
There are several types of change events, consult the API documentation of classes that extends akka.cluster.ClusterEvent.ClusterDomainEvent for details about the events.
Worker Dial-in Example
Let's take a look at an example that illustrates how workers, here named backend, can detect and register to new master nodes, here named frontend.
The example application provides a service to transform text. When some text is sent to one of the frontend services, it will be delegated to one of the backend workers, which performs the transformation job, and sends the result back to the original client. New backend nodes, as well as new frontend nodes, can be added or removed to the cluster dynamically.
In this example the following imports are used:
import language.postfixOps
import scala.concurrent.duration._
import akka.actor.Actor
import akka.actor.ActorRef
import akka.actor.ActorSystem
import akka.actor.Props
import akka.actor.RootActorPath
import akka.actor.Terminated
import akka.cluster.Cluster
import akka.cluster.ClusterEvent.CurrentClusterState
import akka.cluster.ClusterEvent.MemberUp
import akka.cluster.Member
import akka.cluster.MemberStatus
import akka.pattern.ask
import akka.util.Timeout
Messages:
case class TransformationJob(text: String)
case class TransformationResult(text: String)
case class JobFailed(reason: String, job: TransformationJob)
case object BackendRegistration
The backend worker that performs the transformation job:
class TransformationBackend extends Actor {
val cluster = Cluster(context.system)
// subscribe to cluster changes, MemberUp
// re-subscribe when restart
override def preStart(): Unit = cluster.subscribe(self, classOf[MemberUp])
override def postStop(): Unit = cluster.unsubscribe(self)
def receive = {
case TransformationJob(text) ⇒ sender ! TransformationResult(text.toUpperCase)
case state: CurrentClusterState ⇒
state.members.filter(_.status == MemberStatus.Up) foreach register
case MemberUp(m) ⇒ register(m)
}
// try to register to all nodes, even though there
// might not be any frontend on all nodes
def register(member: Member): Unit =
context.actorFor(RootActorPath(member.address) / "user" / "frontend") !
BackendRegistration
}
Note that the TransformationBackend actor subscribes to cluster events to detect new, potential, frontend nodes, and send them a registration message so that they know that they can use the backend worker.
The frontend that receives user jobs and delegates to one of the registered backend workers:
class TransformationFrontend extends Actor {
var backends = IndexedSeq.empty[ActorRef]
var jobCounter = 0
def receive = {
case job: TransformationJob if backends.isEmpty ⇒
sender ! JobFailed("Service unavailable, try again later", job)
case job: TransformationJob ⇒
jobCounter += 1
backends(jobCounter % backends.size) forward job
case BackendRegistration if !backends.contains(sender) ⇒
context watch sender
backends = backends :+ sender
case Terminated(a) ⇒
backends = backends.filterNot(_ == a)
}
}
Note that the TransformationFrontend actor watch the registered backend to be able to remove it from its list of availble backend workers. Death watch uses the cluster failure detector for nodes in the cluster, i.e. it detects network failures and JVM crashes, in addition to graceful termination of watched actor.
This example is included in akka-samples/akka-sample-cluster and you can try by starting nodes in different terminal windows. For example, starting 2 frontend nodes and 3 backend nodes:
sbt
project akka-sample-cluster-experimental
run-main sample.cluster.transformation.TransformationFrontend 2551
run-main sample.cluster.transformation.TransformationBackend 2552
run-main sample.cluster.transformation.TransformationBackend
run-main sample.cluster.transformation.TransformationBackend
run-main sample.cluster.transformation.TransformationFrontend
Note
The above example should probably be designed as two separate, frontend/backend, clusters, when there is a cluster client for decoupling clusters.
How To Startup when Cluster Size Reached
A common use case is to start actors after the cluster has been initialized, members have joined, and the cluster has reached a certain size.
With a configuration option you can define required number of members before the leader changes member status of 'Joining' members to 'Up'.
akka.cluster.min-nr-of-members = 3
You can start the actors in a registerOnMemberUp callback, which will be invoked when the current member status is changed tp 'Up', i.e. the cluster has at least the defined number of members.
Cluster(system) registerOnMemberUp {
system.actorOf(Props(new FactorialFrontend(upToN, repeat = true)),
name = "factorialFrontend")
}
This callback can be used for other things than starting actors.
Cluster Singleton Pattern
For some use cases it is convenient and sometimes also mandatory to ensure that you have exactly one actor of a certain type running somewhere in the cluster.
This can be implemented by subscribing to LeaderChanged events, but there are several corner cases to consider. Therefore, this specific use case is made easily accessible by the Cluster Singleton Pattern in the contrib module. You can use it as is, or adjust to fit your specific needs.
Failure Detector
The nodes in the cluster monitor each other by sending heartbeats to detect if a node is unreachable from the rest of the cluster. The heartbeat arrival times is interpreted by an implementation of The Phi Accrual Failure Detector.
The suspicion level of failure is given by a value called phi. The basic idea of the phi failure detector is to express the value of phi on a scale that is dynamically adjusted to reflect current network conditions.
The value of phi is calculated as:
phi = -log10(1 - F(timeSinceLastHeartbeat))
where F is the cumulative distribution function of a normal distribution with mean and standard deviation estimated from historical heartbeat inter-arrival times.
In the Configuration you can adjust the akka.cluster.failure-detector.threshold to define when a phi value is considered to be a failure.
A low threshold is prone to generate many false positives but ensures a quick detection in the event of a real crash. Conversely, a high threshold generates fewer mistakes but needs more time to detect actual crashes. The default threshold is 8 and is appropriate for most situations. However in cloud environments, such as Amazon EC2, the value could be increased to 12 in order to account for network issues that sometimes occur on such platforms.
The following chart illustrates how phi increase with increasing time since the previous heartbeat.
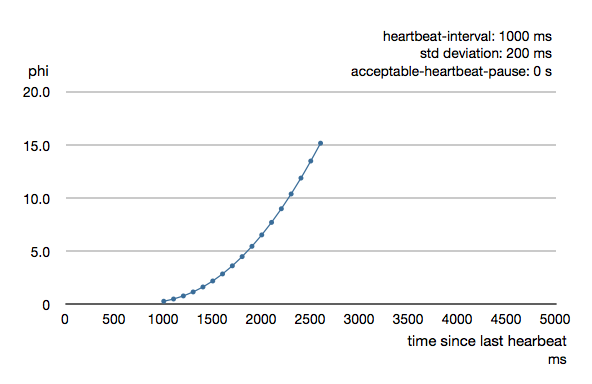
Phi is calculated from the mean and standard deviation of historical inter arrival times. The previous chart is an example for standard deviation of 200 ms. If the heartbeats arrive with less deviation the curve becomes steeper, i.e. it's possible to determine failure more quickly. The curve looks like this for a standard deviation of 100 ms.
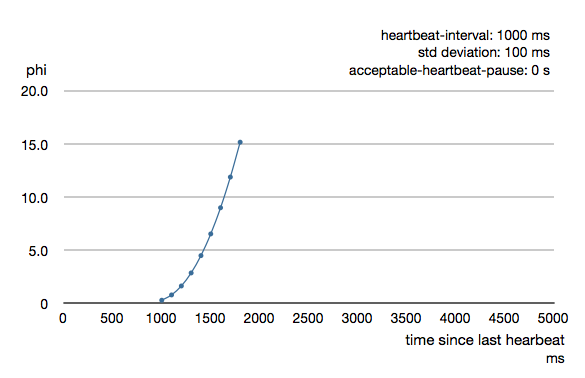
To be able to survive sudden abnormalities, such as garbage collection pauses and transient network failures the failure detector is configured with a margin, akka.cluster.failure-detector.acceptable-heartbeat-pause. You may want to adjust the Configuration of this depending on you environment. This is how the curve looks like for acceptable-heartbeat-pause configured to 3 seconds.
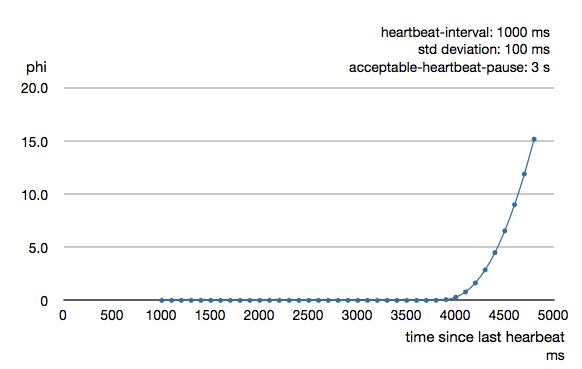
Cluster Aware Routers
All routers can be made aware of member nodes in the cluster, i.e. deploying new routees or looking up routees on nodes in the cluster. When a node becomes unavailble or leaves the cluster the routees of that node are automatically unregistered from the router. When new nodes join the cluster additional routees are added to the router, according to the configuration.
When using a router with routees looked up on the cluster member nodes, i.e. the routees are already running, the configuration for a router looks like this:
akka.actor.deployment {
/statsService/workerRouter {
router = consistent-hashing
nr-of-instances = 100
cluster {
enabled = on
routees-path = "/user/statsWorker"
allow-local-routees = on
}
}
}
It's the relative actor path defined in routees-path that identify what actor to lookup.
nr-of-instances defines total number of routees in the cluster, but there will not be more than one per node. Setting nr-of-instances to a high value will result in new routees added to the router when nodes join the cluster.
The same type of router could also have been defined in code:
import akka.cluster.routing.ClusterRouterConfig
import akka.cluster.routing.ClusterRouterSettings
import akka.routing.ConsistentHashingRouter
val workerRouter = context.actorOf(Props[StatsWorker].withRouter(
ClusterRouterConfig(ConsistentHashingRouter(), ClusterRouterSettings(
totalInstances = 100, routeesPath = "/user/statsWorker",
allowLocalRoutees = true))),
name = "workerRouter2")
When using a router with routees created and deployed on the cluster member nodes the configuration for a router looks like this:
akka.actor.deployment {
/singleton/statsService/workerRouter {
router = consistent-hashing
nr-of-instances = 100
cluster {
enabled = on
max-nr-of-instances-per-node = 3
allow-local-routees = off
}
}
}
nr-of-instances defines total number of routees in the cluster, but the number of routees per node, max-nr-of-instances-per-node, will not be exceeded. Setting nr-of-instances to a high value will result in creating and deploying additional routees when new nodes join the cluster.
The same type of router could also have been defined in code:
import akka.cluster.routing.ClusterRouterConfig
import akka.cluster.routing.ClusterRouterSettings
import akka.routing.ConsistentHashingRouter
val workerRouter = context.actorOf(Props[StatsWorker].withRouter(
ClusterRouterConfig(ConsistentHashingRouter(), ClusterRouterSettings(
totalInstances = 100, maxInstancesPerNode = 3,
allowLocalRoutees = false))),
name = "workerRouter3")
See Configuration section for further descriptions of the settings.
Router Example with Lookup of Routees
Let's take a look at how to use cluster aware routers.
The example application provides a service to calculate statistics for a text. When some text is sent to the service it splits it into words, and delegates the task to count number of characters in each word to a separate worker, a routee of a router. The character count for each word is sent back to an aggregator that calculates the average number of characters per word when all results have been collected.
In this example we use the following imports:
import language.postfixOps
import scala.concurrent.forkjoin.ThreadLocalRandom
import scala.concurrent.duration._
import com.typesafe.config.ConfigFactory
import akka.actor.Actor
import akka.actor.ActorLogging
import akka.actor.ActorRef
import akka.actor.ActorSystem
import akka.actor.Address
import akka.actor.PoisonPill
import akka.actor.Props
import akka.actor.ReceiveTimeout
import akka.actor.RelativeActorPath
import akka.actor.RootActorPath
import akka.cluster.Cluster
import akka.cluster.ClusterEvent._
import akka.cluster.MemberStatus
import akka.contrib.pattern.ClusterSingletonManager
import akka.routing.FromConfig
import akka.routing.ConsistentHashingRouter.ConsistentHashableEnvelope
import akka.pattern.ask
import akka.pattern.pipe
import akka.util.Timeout
Messages:
case class StatsJob(text: String)
case class StatsResult(meanWordLength: Double)
case class JobFailed(reason: String)
The worker that counts number of characters in each word:
class StatsWorker extends Actor {
var cache = Map.empty[String, Int]
def receive = {
case word: String ⇒
val length = cache.get(word) match {
case Some(x) ⇒ x
case None ⇒
val x = word.length
cache += (word -> x)
x
}
sender ! length
}
}
The service that receives text from users and splits it up into words, delegates to workers and aggregates:
class StatsService extends Actor {
val workerRouter = context.actorOf(Props[StatsWorker].withRouter(FromConfig),
name = "workerRouter")
def receive = {
case StatsJob(text) if text != "" ⇒
val words = text.split(" ")
val replyTo = sender // important to not close over sender
// create actor that collects replies from workers
val aggregator = context.actorOf(Props(
new StatsAggregator(words.size, replyTo)))
words foreach { word ⇒
workerRouter.tell(
ConsistentHashableEnvelope(word, word), aggregator)
}
}
}
class StatsAggregator(expectedResults: Int, replyTo: ActorRef) extends Actor {
var results = IndexedSeq.empty[Int]
context.setReceiveTimeout(3 seconds)
def receive = {
case wordCount: Int ⇒
results = results :+ wordCount
if (results.size == expectedResults) {
val meanWordLength = results.sum.toDouble / results.size
replyTo ! StatsResult(meanWordLength)
context.stop(self)
}
case ReceiveTimeout ⇒
replyTo ! JobFailed("Service unavailable, try again later")
context.stop(self)
}
}
Note, nothing cluster specific so far, just plain actors.
We can use these actors with two different types of router setup. Either with lookup of routees, or with create and deploy of routees. Remember, routees are the workers in this case.
We start with the router setup with lookup of routees. All nodes start StatsService and StatsWorker actors and the router is configured with routees-path:
val system = ActorSystem("ClusterSystem", ConfigFactory.parseString("""
akka.actor.deployment {
/statsService/workerRouter {
router = consistent-hashing
nr-of-instances = 100
cluster {
enabled = on
routees-path = "/user/statsWorker"
allow-local-routees = on
}
}
}
""").withFallback(ConfigFactory.load()))
system.actorOf(Props[StatsWorker], name = "statsWorker")
system.actorOf(Props[StatsService], name = "statsService")
This means that user requests can be sent to StatsService on any node and it will use StatsWorker on all nodes. There can only be one worker per node, but that worker could easily fan out to local children if more parallelism is needed.
This example is included in akka-samples/akka-sample-cluster and you can try by starting nodes in different terminal windows. For example, starting 3 service nodes and 1 client:
sbt
project akka-sample-cluster-experimental
run-main sample.cluster.stats.StatsSample 2551
run-main sample.cluster.stats.StatsSample 2552
run-main sample.cluster.stats.StatsSampleClient
run-main sample.cluster.stats.StatsSample
Router Example with Remote Deployed Routees
The above setup is nice for this example, but we will also take a look at how to use a single master node that creates and deploys workers. To keep track of a single master we use the Cluster Singleton Pattern in the contrib module. The ClusterSingletonManager is started on each node.
system.actorOf(Props(new ClusterSingletonManager(
singletonProps = _ ⇒ Props[StatsService], singletonName = "statsService",
terminationMessage = PoisonPill)), name = "singleton")
We also need an actor on each node that keeps track of where current single master exists and delegates jobs to the StatsService.
class StatsFacade extends Actor with ActorLogging {
import context.dispatcher
val cluster = Cluster(context.system)
var currentMaster: Option[Address] = None
// subscribe to cluster changes, LeaderChanged
// re-subscribe when restart
override def preStart(): Unit = cluster.subscribe(self, classOf[LeaderChanged])
override def postStop(): Unit = cluster.unsubscribe(self)
def receive = {
case job: StatsJob if currentMaster.isEmpty ⇒
sender ! JobFailed("Service unavailable, try again later")
case job: StatsJob ⇒
implicit val timeout = Timeout(5.seconds)
currentMaster foreach { address ⇒
val service = context.actorFor(RootActorPath(address) /
"user" / "singleton" / "statsService")
service ? job recover {
case _ ⇒ JobFailed("Service unavailable, try again later")
} pipeTo sender
}
case state: CurrentClusterState ⇒ currentMaster = state.leader
case LeaderChanged(leader) ⇒ currentMaster = leader
}
}
The StatsFacade receives text from users and delegates to the current StatsService, the single master. It listens to cluster events to lookup the StatsService on the leader node. The master runs on the same node as the leader of the cluster members, which is nothing more than the address currently sorted first in the member ring, i.e. it can change when new nodes join or when current leader leaves.
All nodes start StatsFacade and the ClusterSingletonManager. The router is now configured like this:
val system = ActorSystem("ClusterSystem", ConfigFactory.parseString("""
akka.actor.deployment {
/singleton/statsService/workerRouter {
router = consistent-hashing
nr-of-instances = 100
cluster {
enabled = on
max-nr-of-instances-per-node = 3
allow-local-routees = off
}
}
}
""").withFallback(ConfigFactory.load()))
This example is included in akka-samples/akka-sample-cluster and you can try by starting nodes in different terminal windows. For example, starting 3 service nodes and 1 client:
run-main sample.cluster.stats.StatsSampleOneMaster 2551
run-main sample.cluster.stats.StatsSampleOneMaster 2552
run-main sample.cluster.stats.StatsSampleOneMasterClient
run-main sample.cluster.stats.StatsSampleOneMaster
Note
The above example will be simplified when the cluster handles automatic actor partitioning.
Cluster Metrics
The member nodes of the cluster collects system health metrics and publishes that to other nodes and to registered subscribers. This information is primarily used for load-balancing routers.
Hyperic Sigar
The built-in metrics is gathered from JMX MBeans, and optionally you can use Hyperic Sigar for a wider and more accurate range of metrics compared to what can be retrieved from ordinary MBeans. Sigar is using a native OS library. To enable usage of Sigar you need to add the directory of the native library to -Djava.libarary.path=<path_of_sigar_libs> add the following dependency:
"org.hyperic" % "sigar" % "1.6.4"
Adaptive Load Balancing
The AdaptiveLoadBalancingRouter performs load balancing of messages to cluster nodes based on the cluster metrics data. It uses random selection of routees with probabilities derived from the remaining capacity of the corresponding node. It can be configured to use a specific MetricsSelector to produce the probabilities, a.k.a. weights:
- heap / HeapMetricsSelector - Used and max JVM heap memory. Weights based on remaining heap capacity; (max - used) / max
- load / SystemLoadAverageMetricsSelector - System load average for the past 1 minute, corresponding value can be found in top of Linux systems. The system is possibly nearing a bottleneck if the system load average is nearing number of cpus/cores. Weights based on remaining load capacity; 1 - (load / processors)
- cpu / CpuMetricsSelector - CPU utilization in percentage, sum of User + Sys + Nice + Wait. Weights based on remaining cpu capacity; 1 - utilization
- mix / MixMetricsSelector - Combines heap, cpu and load. Weights based on mean of remaining capacity of the combined selectors.
- Any custom implementation of akka.cluster.routing.MetricsSelector
The collected metrics values are smoothed with exponential weighted moving average. In the Configuration you can adjust how quickly past data is decayed compared to new data.
Let's take a look at this router in action.
In this example the following imports are used:
import scala.annotation.tailrec
import scala.concurrent.Future
import com.typesafe.config.ConfigFactory
import akka.actor.Actor
import akka.actor.ActorLogging
import akka.actor.ActorRef
import akka.actor.ActorSystem
import akka.actor.Props
import akka.pattern.pipe
import akka.routing.FromConfig
The backend worker that performs the factorial calculation:
class FactorialBackend extends Actor with ActorLogging {
import context.dispatcher
def receive = {
case (n: Int) ⇒
Future(factorial(n)) map { result ⇒ (n, result) } pipeTo sender
}
def factorial(n: Int): BigInt = {
@tailrec def factorialAcc(acc: BigInt, n: Int): BigInt = {
if (n <= 1) acc
else factorialAcc(acc * n, n - 1)
}
factorialAcc(BigInt(1), n)
}
}
The frontend that receives user jobs and delegates to the backends via the router:
class FactorialFrontend(upToN: Int, repeat: Boolean) extends Actor with ActorLogging {
val backend = context.actorOf(Props[FactorialBackend].withRouter(FromConfig),
name = "factorialBackendRouter")
override def preStart(): Unit = sendJobs()
def receive = {
case (n: Int, factorial: BigInt) ⇒
if (n == upToN) {
log.debug("{}! = {}", n, factorial)
if (repeat) sendJobs()
}
}
def sendJobs(): Unit = {
log.info("Starting batch of factorials up to [{}]", upToN)
1 to upToN foreach { backend ! _ }
}
}
As you can see, the router is defined in the same way as other routers, and in this case it's configured as follows:
akka.actor.deployment {
/factorialFrontend/factorialBackendRouter = {
router = adaptive
# metrics-selector = heap
# metrics-selector = load
# metrics-selector = cpu
metrics-selector = mix
nr-of-instances = 100
cluster {
enabled = on
routees-path = "/user/factorialBackend"
allow-local-routees = off
}
}
}
It's only router type adaptive and the metrics-selector that is specific to this router, other things work in the same way as other routers.
The same type of router could also have been defined in code:
import akka.cluster.routing.ClusterRouterConfig
import akka.cluster.routing.ClusterRouterSettings
import akka.cluster.routing.AdaptiveLoadBalancingRouter
import akka.cluster.routing.HeapMetricsSelector
val backend = context.actorOf(Props[FactorialBackend].withRouter(
ClusterRouterConfig(AdaptiveLoadBalancingRouter(HeapMetricsSelector),
ClusterRouterSettings(
totalInstances = 100, routeesPath = "/user/statsWorker",
allowLocalRoutees = true))),
name = "factorialBackendRouter2")
import akka.cluster.routing.ClusterRouterConfig
import akka.cluster.routing.ClusterRouterSettings
import akka.cluster.routing.AdaptiveLoadBalancingRouter
import akka.cluster.routing.SystemLoadAverageMetricsSelector
val backend = context.actorOf(Props[FactorialBackend].withRouter(
ClusterRouterConfig(AdaptiveLoadBalancingRouter(
SystemLoadAverageMetricsSelector), ClusterRouterSettings(
totalInstances = 100, maxInstancesPerNode = 3,
allowLocalRoutees = false))),
name = "factorialBackendRouter3")
This example is included in akka-samples/akka-sample-cluster and you can try by starting nodes in different terminal windows. For example, starting 3 backend nodes and one frontend:
sbt
project akka-sample-cluster-experimental
run-main sample.cluster.factorial.FactorialBackend 2551
run-main sample.cluster.factorial.FactorialBackend 2552
run-main sample.cluster.factorial.FactorialBackend
run-main sample.cluster.factorial.FactorialFrontend
Press ctrl-c in the terminal window of the frontend to stop the factorial calculations.
Subscribe to Metrics Events
It's possible to subscribe to the metrics events directly to implement other functionality.
import akka.cluster.Cluster
import akka.cluster.ClusterEvent.ClusterMetricsChanged
import akka.cluster.ClusterEvent.CurrentClusterState
import akka.cluster.NodeMetrics
import akka.cluster.StandardMetrics.HeapMemory
import akka.cluster.StandardMetrics.Cpu
class MetricsListener extends Actor with ActorLogging {
val selfAddress = Cluster(context.system).selfAddress
// subscribe to ClusterMetricsChanged
// re-subscribe when restart
override def preStart(): Unit =
Cluster(context.system).subscribe(self, classOf[ClusterMetricsChanged])
override def postStop(): Unit =
Cluster(context.system).unsubscribe(self)
def receive = {
case ClusterMetricsChanged(clusterMetrics) ⇒
clusterMetrics.filter(_.address == selfAddress) foreach { nodeMetrics ⇒
logHeap(nodeMetrics)
logCpu(nodeMetrics)
}
case state: CurrentClusterState ⇒ // ignore
}
def logHeap(nodeMetrics: NodeMetrics): Unit = nodeMetrics match {
case HeapMemory(address, timestamp, used, committed, max) ⇒
log.info("Used heap: {} MB", used.doubleValue / 1024 / 1024)
case _ ⇒ // no heap info
}
def logCpu(nodeMetrics: NodeMetrics): Unit = nodeMetrics match {
case Cpu(address, timestamp, Some(systemLoadAverage), cpuCombined, processors) ⇒
log.info("Load: {} ({} processors)", systemLoadAverage, processors)
case _ ⇒ // no cpu info
}
}
Custom Metrics Collector
You can plug-in your own metrics collector instead of akka.cluster.SigarMetricsCollector or akka.cluster.JmxMetricsCollector. Look at those two implementations for inspiration. The implementation class can be defined in the Configuration.
How to Test
Multi Node Testing is useful for testing cluster applications.
Set up your project according to the instructions in Multi Node Testing and Multi JVM Testing, i.e. add the sbt-multi-jvm plugin and the dependency to akka-remote-tests-experimental.
First, as described in Multi Node Testing, we need some scaffolding to configure the MultiNodeSpec. Define the participating roles and their Configuration in an object extending MultiNodeConfig:
import akka.remote.testkit.MultiNodeConfig
import com.typesafe.config.ConfigFactory
object StatsSampleSpecConfig extends MultiNodeConfig {
// register the named roles (nodes) of the test
val first = role("first")
val second = role("second")
val third = role("thrid")
// this configuration will be used for all nodes
// note that no fixed host names and ports are used
commonConfig(ConfigFactory.parseString("""
akka.actor.provider = "akka.cluster.ClusterActorRefProvider"
akka.remote.log-remote-lifecycle-events = off
akka.cluster.auto-join = off
# don't use sigar for tests, native lib not in path
akka.cluster.metrics.collector-class = akka.cluster.JmxMetricsCollector
// router lookup config ...
"""))
}
Define one concrete test class for each role/node. These will be instantiated on the different nodes (JVMs). They can be implemented differently, but often they are the same and extend an abstract test class, as illustrated here.
// need one concrete test class per node
class StatsSampleSpecMultiJvmNode1 extends StatsSampleSpec
class StatsSampleSpecMultiJvmNode2 extends StatsSampleSpec
class StatsSampleSpecMultiJvmNode3 extends StatsSampleSpec
Note the naming convention of these classes. The name of the classes must end with MultiJvmNode1, MultiJvmNode2 and so on. It's possible to define another suffix to be used by the sbt-multi-jvm, but the default should be fine in most cases.
Then the abstract MultiNodeSpec, which takes the MultiNodeConfig as constructor parameter.
import org.scalatest.BeforeAndAfterAll
import org.scalatest.WordSpec
import org.scalatest.matchers.MustMatchers
import akka.remote.testkit.MultiNodeSpec
import akka.testkit.ImplicitSender
abstract class StatsSampleSpec extends MultiNodeSpec(StatsSampleSpecConfig)
with WordSpec with MustMatchers with BeforeAndAfterAll
with ImplicitSender {
import StatsSampleSpecConfig._
override def initialParticipants = roles.size
override def beforeAll() = multiNodeSpecBeforeAll()
override def afterAll() = multiNodeSpecAfterAll()
Most of this can of course be extracted to a separate trait to avoid repeating this in all your tests.
Typically you begin your test by starting up the cluster and let the members join, and create some actors. That can be done like this:
"illustrate how to startup cluster" in within(15 seconds) {
Cluster(system).subscribe(testActor, classOf[MemberUp])
expectMsgClass(classOf[CurrentClusterState])
val firstAddress = node(first).address
val secondAddress = node(second).address
val thirdAddress = node(third).address
Cluster(system) join firstAddress
system.actorOf(Props[StatsWorker], "statsWorker")
system.actorOf(Props[StatsService], "statsService")
expectMsgAllOf(
MemberUp(Member(firstAddress, MemberStatus.Up)),
MemberUp(Member(secondAddress, MemberStatus.Up)),
MemberUp(Member(thirdAddress, MemberStatus.Up)))
Cluster(system).unsubscribe(testActor)
testConductor.enter("all-up")
}
From the test you interact with the cluster using the Cluster extension, e.g. join.
Cluster(system) join firstAddress
Notice how the testActor from testkit is added as subscriber to cluster changes and then waiting for certain events, such as in this case all members becoming 'Up'.
The above code was running for all roles (JVMs). runOn is a convenient utility to declare that a certain block of code should only run for a specific role.
"show usage of the statsService from one node" in within(15 seconds) {
runOn(second) {
assertServiceOk
}
testConductor.enter("done-2")
}
def assertServiceOk: Unit = {
val service = system.actorFor(node(third) / "user" / "statsService")
// eventually the service should be ok,
// first attempts might fail because worker actors not started yet
awaitCond {
service ! StatsJob("this is the text that will be analyzed")
expectMsgPF() {
case unavailble: JobFailed ⇒ false
case StatsResult(meanWordLength) ⇒
meanWordLength must be(3.875 plusOrMinus 0.001)
true
}
}
}
Once again we take advantage of the facilities in testkit to verify expected behavior. Here using testActor as sender (via ImplicitSender) and verifing the reply with expectMsgPF.
In the above code you can see node(third), which is useful facility to get the root actor reference of the actor system for a specific role. This can also be used to grab the akka.actor.Address of that node.
val firstAddress = node(first).address
val secondAddress = node(second).address
val thirdAddress = node(third).address
JMX
Information and management of the cluster is available as JMX MBeans with the root name akka.Cluster. The JMX information can be displayed with an ordinary JMX console such as JConsole or JVisualVM.
From JMX you can:
- see what members that are part of the cluster
- see status of this node
- join this node to another node in cluster
- mark any node in the cluster as down
- tell any node in the cluster to leave
Member nodes are identified with their address, in format akka://actor-system-name@hostname:port.
Command Line Management
The cluster can be managed with the script bin/akka-cluster provided in the Akka distribution.
Run it without parameters to see instructions about how to use the script:
Usage: bin/akka-cluster <node-hostname:jmx-port> <command> ...
Supported commands are:
join <node-url> - Sends request a JOIN node with the specified URL
leave <node-url> - Sends a request for node with URL to LEAVE the cluster
down <node-url> - Sends a request for marking node with URL as DOWN
member-status - Asks the member node for its current status
members - Asks the cluster for addresses of current members
unreachable - Asks the cluster for addresses of unreachable members
cluster-status - Asks the cluster for its current status (member ring,
unavailable nodes, meta data etc.)
leader - Asks the cluster who the current leader is
is-singleton - Checks if the cluster is a singleton cluster (single
node cluster)
is-available - Checks if the member node is available
Where the <node-url> should be on the format of
'akka://actor-system-name@hostname:port'
Examples: bin/akka-cluster localhost:9999 is-available
bin/akka-cluster localhost:9999 join akka://MySystem@darkstar:2552
bin/akka-cluster localhost:9999 cluster-status
To be able to use the script you must enable remote monitoring and management when starting the JVMs of the cluster nodes, as described in Monitoring and Management Using JMX Technology
Example of system properties to enable remote monitoring and management:
java -Dcom.sun.management.jmxremote.port=9999 \
-Dcom.sun.management.jmxremote.authenticate=false \
-Dcom.sun.management.jmxremote.ssl=false
Configuration
There are several configuration properties for the cluster. We refer to the following reference file for more information:
######################################
# Akka Cluster Reference Config File #
######################################
# This is the reference config file that contains all the default settings.
# Make your edits/overrides in your application.conf.
akka {
cluster {
# Initial contact points of the cluster.
# The nodes to join at startup if auto-join = on.
# Comma separated full URIs defined by a string on the form of
# "akka://system@hostname:port"
# Leave as empty if the node should be a singleton cluster.
seed-nodes = []
# how long to wait for one of the seed nodes to reply to initial join request
seed-node-timeout = 5s
# Automatic join the seed-nodes at startup.
# If seed-nodes is empty it will join itself and become a single node cluster.
auto-join = on
# Should the 'leader' in the cluster be allowed to automatically mark
# unreachable nodes as DOWN?
# Using auto-down implies that two separate clusters will automatically be
# formed in case of network partition.
auto-down = off
# Minimum required number of members before the leader changes member status
# of 'Joining' members to 'Up'. Typically used together with
# 'Cluster.registerOnMemberUp' to defer some action, such as starting actors,
# until the cluster has reached a certain size.
min-nr-of-members = 1
# Enable or disable JMX MBeans for management of the cluster
jmx.enabled = on
# how long should the node wait before starting the periodic tasks
# maintenance tasks?
periodic-tasks-initial-delay = 1s
# how often should the node send out gossip information?
gossip-interval = 1s
# how often should the leader perform maintenance tasks?
leader-actions-interval = 1s
# how often should the node move nodes, marked as unreachable by the failure
# detector, out of the membership ring?
unreachable-nodes-reaper-interval = 1s
# How often the current internal stats should be published.
# A value of 0 s can be used to always publish the stats, when it happens.
publish-stats-interval = 10s
# The id of the dispatcher to use for cluster actors. If not specified
# default dispatcher is used.
# If specified you need to define the settings of the actual dispatcher.
use-dispatcher = ""
# Gossip to random node with newer or older state information, if any with
# this probability. Otherwise Gossip to any random live node.
# Probability value is between 0.0 and 1.0. 0.0 means never, 1.0 means always.
gossip-different-view-probability = 0.8
# Limit number of merge conflicts per second that are handled. If the limit is
# exceeded the conflicting gossip messages are dropped and will reappear later.
max-gossip-merge-rate = 5.0
failure-detector {
# FQCN of the failure detector implementation.
# It must implement akka.cluster.FailureDetector and
# have constructor with akka.actor.ActorSystem and
# akka.cluster.ClusterSettings parameters
implementation-class = "akka.cluster.AccrualFailureDetector"
# how often should the node send out heartbeats?
heartbeat-interval = 1s
# Number of member nodes that each member will send heartbeat messages to,
# i.e. each node will be monitored by this number of other nodes.
monitored-by-nr-of-members = 5
# defines the failure detector threshold
# A low threshold is prone to generate many wrong suspicions but ensures
# a quick detection in the event of a real crash. Conversely, a high
# threshold generates fewer mistakes but needs more time to detect
# actual crashes
threshold = 8.0
# Minimum standard deviation to use for the normal distribution in
# AccrualFailureDetector. Too low standard deviation might result in
# too much sensitivity for sudden, but normal, deviations in heartbeat
# inter arrival times.
min-std-deviation = 100 ms
# Number of potentially lost/delayed heartbeats that will be
# accepted before considering it to be an anomaly.
# It is a factor of heartbeat-interval.
# This margin is important to be able to survive sudden, occasional,
# pauses in heartbeat arrivals, due to for example garbage collect or
# network drop.
acceptable-heartbeat-pause = 3s
# Number of samples to use for calculation of mean and standard deviation of
# inter-arrival times.
max-sample-size = 1000
# When a node stops sending heartbeats to another node it will end that
# with this number of EndHeartbeat messages, which will remove the
# monitoring from the failure detector.
nr-of-end-heartbeats = 8
# When no expected heartbeat message has been received an explicit
# heartbeat request is sent to the node that should emit heartbeats.
heartbeat-request {
# Grace period until an explicit heartbeat request is sent
grace-period = 10 s
# After the heartbeat request has been sent the first failure detection
# will start after this period, even though no heartbeat mesage has
# been received.
expected-response-after = 3 s
# Cleanup of obsolete heartbeat requests
time-to-live = 60 s
}
}
metrics {
# Enable or disable metrics collector for load-balancing nodes.
enabled = on
# FQCN of the metrics collector implementation.
# It must implement akka.cluster.cluster.MetricsCollector and
# have constructor with akka.actor.ActorSystem parameter.
# The default SigarMetricsCollector uses JMX and Hyperic SIGAR, if SIGAR
# is on the classpath, otherwise only JMX.
collector-class = "akka.cluster.SigarMetricsCollector"
# How often metrics are sampled on a node.
# Shorter interval will collect the metrics more often.
collect-interval = 3s
# How often a node publishes metrics information.
gossip-interval = 3s
# How quickly the exponential weighting of past data is decayed compared to
# new data. Set lower to increase the bias toward newer values.
# The relevance of each data sample is halved for every passing half-life duration,
# i.e. after 4 times the half-life, a data sample’s relevance is reduced to 6% of
# its original relevance. The initial relevance of a data sample is given by
# 1 – 0.5 ^ (collect-interval / half-life).
# See http://en.wikipedia.org/wiki/Moving_average#Exponential_moving_average
moving-average-half-life = 12s
}
# If the tick-duration of the default scheduler is longer than the
# tick-duration configured here a dedicated scheduler will be used for
# periodic tasks of the cluster, otherwise the default scheduler is used.
# See akka.scheduler settings for more details about the HashedWheelTimer.
scheduler {
tick-duration = 33ms
ticks-per-wheel = 512
}
# Netty blocks when sending to broken connections, and this circuit breaker
# is used to reduce connect attempts to broken connections.
send-circuit-breaker {
max-failures = 3
call-timeout = 2 s
reset-timeout = 30 s
}
}
# Default configuration for routers
actor.deployment.default {
# MetricsSelector to use
# - available: "mix", "heap", "cpu", "load"
# - or: Fully qualified class name of the MetricsSelector class.
# The class must extend akka.cluster.routing.MetricsSelector
# and have a constructor with com.typesafe.config.Config
# parameter.
# - default is "mix"
metrics-selector = mix
}
actor.deployment.default.cluster {
# enable cluster aware router that deploys to nodes in the cluster
enabled = off
# Maximum number of routees that will be deployed on each cluster
# member node.
# Note that nr-of-instances defines total number of routees, but
# number of routees per node will not be exceeded, i.e. if you
# define nr-of-instances = 50 and max-nr-of-instances-per-node = 2
# it will deploy 2 routees per new member in the cluster, up to
# 25 members.
max-nr-of-instances-per-node = 1
# Defines if routees are allowed to be located on the same node as
# the head router actor, or only on remote nodes.
# Useful for master-worker scenario where all routees are remote.
allow-local-routees = on
# Actor path of the routees to lookup with actorFor on the member
# nodes in the cluster. E.g. "/user/myservice". If this isn't defined
# the routees will be deployed instead of looked up.
# max-nr-of-instances-per-node should not be configured (default value is 1)
# when routees-path is defined.
routees-path = ""
}
}
Cluster Scheduler
It is recommended that you change the tick-duration to 33 ms or less of the default scheduler when using cluster, if you don't need to have it configured to a longer duration for other reasons. If you don't do this a dedicated scheduler will be used for periodic tasks of the cluster, which introduce the extra overhead of another thread.
# shorter tick-duration of default scheduler when using cluster
akka.scheduler.tick-duration = 33ms
Contents
