Software Transactional Memory (Scala)
Module stability: SOLID
Overview of STM
An STM turns the Java heap into a transactional data set with begin/commit/rollback semantics. Very much like a regular database. It implements the first three letters in ACID; ACI: * Atomic * Consistent * Isolated
Generally, the STM is not needed very often when working with Akka. Some use-cases (that we can think of) are:
- When you really need composable message flows across many actors updating their internal local state but need them to do that atomically in one big transaction. Might not be often, but when you do need this then you are screwed without it.
- When you want to share a datastructure across actors.
- When you need to use the persistence modules.
Akka’s STM implements the concept in Clojure’s STM view on state in general. Please take the time to read this excellent document and view this presentation by Rich Hickey (the genius behind Clojure), since it forms the basis of Akka’s view on STM and state in general.
The STM is based on Transactional References (referred to as Refs). Refs are memory cells, holding an (arbitrary) immutable value, that implement CAS (Compare-And-Swap) semantics and are managed and enforced by the STM for coordinated changes across many Refs. They are implemented using the excellent Multiverse STM.
Working with immutable collections can sometimes give bad performance due to extensive copying. Scala provides so-called persistent datastructures which makes working with immutable collections fast. They are immutable but with constant time access and modification. They use structural sharing and an insert or update does not ruin the old structure, hence “persistent”. Makes working with immutable composite types fast. The persistent datastructures currently consist of a Map and Vector.
Simple example
Here is a simple example of an incremental counter using STM. This shows creating a Ref, a transactional reference, and then modifying it within a transaction, which is delimited by atomic.
import akka.stm._
val ref = Ref(0)
def counter = atomic {
ref alter (_ + 1)
}
counter
// -> 1
counter
// -> 2
Ref
Refs (transactional references) are mutable references to values and through the STM allow the safe sharing of mutable data. Refs separate identity from value. To ensure safety the value stored in a Ref should be immutable (they can of course contain refs themselves). The value referenced by a Ref can only be accessed or swapped within a transaction. If a transaction is not available, the call will be executed in its own transaction (the call will be atomic). This is a different approach than the Clojure Refs, where a missing transaction results in an error.
Creating a Ref
You can create a Ref with or without an initial value.
import akka.stm._
// giving an initial value
val ref = Ref(0)
// specifying a type but no initial value
val ref = Ref[Int]
Accessing the value of a Ref
Use get to access the value of a Ref. Note that if no initial value has been given then the value is initially null.
import akka.stm._
val ref = Ref(0)
atomic {
ref.get
}
// -> 0
If there is a chance that the value of a Ref is null then you can use opt, which will create an Option, either Some(value) or None, or you can provide a default value with getOrElse. You can also check for null using isNull.
import akka.stm._
val ref = Ref[Int]
atomic {
ref.opt // -> None
ref.getOrElse(0) // -> 0
ref.isNull // -> true
}
Changing the value of a Ref
To set a new value for a Ref you can use set (or equivalently swap), which sets the new value and returns the old value.
import akka.stm._
val ref = Ref(0)
atomic {
ref.set(5)
}
// -> 0
atomic {
ref.get
}
// -> 5
You can also use alter which accepts a function that takes the old value and creates a new value of the same type.
import akka.stm._
val ref = Ref(0)
atomic {
ref alter (_ + 5)
}
// -> 5
val inc = (i: Int) => i + 1
atomic {
ref alter inc
}
// -> 6
Refs in for-comprehensions
Ref is monadic and can be used in for-comprehensions.
import akka.stm._
val ref = Ref(1)
atomic {
for (value <- ref) {
// do something with value
}
}
val anotherRef = Ref(3)
atomic {
for {
value1 <- ref
value2 <- anotherRef
} yield (value1 + value2)
}
// -> Ref(4)
val emptyRef = Ref[Int]
atomic {
for {
value1 <- ref
value2 <- emptyRef
} yield (value1 + value2)
}
// -> Ref[Int]
Transactions
A transaction is delimited using atomic.
atomic {
// ...
}
All changes made to transactional objects are isolated from other changes, all make it or non make it (so failure atomicity) and are consistent. With the AkkaSTM you automatically have the Oracle version of the SERIALIZED isolation level, lower isolation is not possible. To make it fully serialized, set the writeskew property that checks if a writeskew problem is allowed to happen.
Retries
A transaction is automatically retried when it runs into some read or write conflict, until the operation completes, an exception (throwable) is thrown or when there are too many retries. When a read or writeconflict is encountered, the transaction uses a bounded exponential backoff to prevent cause more contention and give other transactions some room to complete.
If you are using non transactional resources in an atomic block, there could be problems because a transaction can be retried. If you are using print statements or logging, it could be that they are called more than once. So you need to be prepared to deal with this. One of the possible solutions is to work with a deferred or compensating task that is executed after the transaction aborts or commits.
Unexpected retries
It can happen for the first few executions that you get a few failures of execution that lead to unexpected retries, even though there is not any read or writeconflict. The cause of this is that speculative transaction configuration/selection is used. There are transactions optimized for a single transactional object, for 1..n and for n to unlimited. So based on the execution of the transaction, the system learns; it begins with a cheap one and upgrades to more expensive ones. Once it has learned, it will reuse this knowledge. It can be activated/deactivated using the speculative property on the TransactionFactory. In most cases it is best use the default value (enabled) so you get more out of performance.
Coordinated transactions and Transactors
If you need coordinated transactions across actors or threads then see Transactors (Scala).
Configuring transactions
It’s possible to configure transactions. The atomic method can take an implicit or explicit TransactionFactory, which can determine properties of the transaction. A default transaction factory is used if none is specified explicitly or there is no implicit TransactionFactory in scope.
Configuring transactions with an implicit TransactionFactory:
import akka.stm._
implicit val txFactory = TransactionFactory(readonly = true)
atomic {
// read only transaction
}
Configuring transactions with an explicit TransactionFactory:
import akka.stm._
val txFactory = TransactionFactory(readonly = true)
atomic(txFactory) {
// read only transaction
}
The following settings are possible on a TransactionFactory:
- familyName - Family name for transactions. Useful for debugging.
- readonly - Sets transaction as readonly. Readonly transactions are cheaper.
- maxRetries - The maximum number of times a transaction will retry.
- timeout - The maximum time a transaction will block for.
- trackReads - Whether all reads should be tracked. Needed for blocking operations.
- writeSkew - Whether writeskew is allowed. Disable with care.
- blockingAllowed - Whether explicit retries are allowed.
- interruptible - Whether a blocking transaction can be interrupted.
- speculative - Whether speculative configuration should be enabled.
- quickRelease - Whether locks should be released as quickly as possible (before whole commit).
- propagation - For controlling how nested transactions behave.
- traceLevel - Transaction trace level.
You can also specify the default values for some of these options in akka.conf. Here they are with their default values:
stm {
fair = on # Should global transactions be fair or non-fair (non fair yield better performance)
max-retries = 1000
timeout = 5 # Default timeout for blocking transactions and transaction set (in unit defined by
# the time-unit property)
write-skew = true
blocking-allowed = false
interruptible = false
speculative = true
quick-release = true
propagation = "requires"
trace-level = "none"
}
You can also determine at which level a transaction factory is shared or not shared, which affects the way in which the STM can optimise transactions.
Here is a shared transaction factory for all instances of an actor.
import akka.actor._
import akka.stm._
object MyActor {
implicit val txFactory = TransactionFactory(readonly = true)
}
class MyActor extends Actor {
import MyActor.txFactory
def receive = {
case message: String =>
atomic {
// read only transaction
}
}
}
Here’s a similar example with an individual transaction factory for each instance of an actor.
import akka.actor._
import akka.stm._
class MyActor extends Actor {
implicit val txFactory = TransactionFactory(readonly = true)
def receive = {
case message: String =>
atomic {
// read only transaction
}
}
}
Transaction lifecycle listeners
It’s possible to have code that will only run on the successful commit of a transaction, or when a transaction aborts. You can do this by adding deferred or compensating blocks to a transaction.
import akka.stm._
atomic {
deferred {
// executes when transaction commits
}
compensating {
// executes when transaction aborts
}
}
Blocking transactions
You can block in a transaction until a condition is met by using an explicit retry. To use retry you also need to configure the transaction to allow explicit retries.
Here is an example of using retry to block until an account has enough money for a withdrawal. This is also an example of using actors and STM together.
import akka.stm._
import akka.actor._
import akka.util.duration._
import akka.event.EventHandler
type Account = Ref[Double]
case class Transfer(from: Account, to: Account, amount: Double)
class Transferer extends Actor {
implicit val txFactory = TransactionFactory(blockingAllowed = true, trackReads = true, timeout = 60 seconds)
def receive = {
case Transfer(from, to, amount) =>
atomic {
if (from.get < amount) {
EventHandler.info(this, "not enough money - retrying")
retry
}
EventHandler.info(this, "transferring")
from alter (_ - amount)
to alter (_ + amount)
}
}
}
val account1 = Ref(100.0)
val account2 = Ref(100.0)
val transferer = Actor.actorOf(new Transferer).start()
transferer ! Transfer(account1, account2, 500.0)
// INFO Transferer: not enough money - retrying
atomic { account1 alter (_ + 2000) }
// INFO Transferer: transferring
atomic { account1.get }
// -> 1600.0
atomic { account2.get }
// -> 600.0
transferer.stop()
Alternative blocking transactions
You can also have two alternative blocking transactions, one of which can succeed first, with either-orElse.
import akka.stm._
import akka.actor._
import akka.util.duration._
import akka.event.EventHandler
case class Branch(left: Ref[Int], right: Ref[Int], amount: Int)
class Brancher extends Actor {
implicit val txFactory = TransactionFactory(blockingAllowed = true, trackReads = true, timeout = 60 seconds)
def receive = {
case Branch(left, right, amount) =>
atomic {
either {
if (left.get < amount) {
EventHandler.info(this, "not enough on left - retrying")
retry
}
log.info("going left")
} orElse {
if (right.get < amount) {
EventHandler.info(this, "not enough on right - retrying")
retry
}
log.info("going right")
}
}
}
}
val ref1 = Ref(0)
val ref2 = Ref(0)
val brancher = Actor.actorOf(new Brancher).start()
brancher ! Branch(ref1, ref2, 1)
// INFO Brancher: not enough on left - retrying
// INFO Brancher: not enough on right - retrying
atomic { ref2 alter (_ + 1) }
// INFO Brancher: not enough on left - retrying
// INFO Brancher: going right
brancher.stop()
Transactional datastructures
Akka provides two datastructures that are managed by the STM.
- TransactionalMap
- TransactionalVector
TransactionalMap and TransactionalVector look like regular mutable datastructures, they even implement the standard Scala ‘Map’ and ‘RandomAccessSeq’ interfaces, but they are implemented using persistent datastructures and managed references under the hood. Therefore they are safe to use in a concurrent environment. Underlying TransactionalMap is HashMap, an immutable Map but with near constant time access and modification operations. Similarly TransactionalVector uses a persistent Vector. See the Persistent Datastructures section below for more details.
Like managed references, TransactionalMap and TransactionalVector can only be modified inside the scope of an STM transaction.
IMPORTANT: There have been some problems reported when using transactional datastructures with ‘lazy’ initialization. Avoid that.
Here is how you create these transactional datastructures:
import akka.stm._
// assuming something like
case class User(name: String)
case class Address(location: String)
// using initial values
val map = TransactionalMap("bill" -> User("bill"))
val vector = TransactionalVector(Address("somewhere"))
// specifying types
val map = TransactionalMap[String, User]
val vector = TransactionalVector[Address]
TransactionalMap and TransactionalVector wrap persistent datastructures with transactional references and provide a standard Scala interface. This makes them convenient to use.
Here is an example of using a Ref and a HashMap directly:
import akka.stm._
import scala.collection.immutable.HashMap
case class User(name: String)
val ref = Ref(HashMap[String, User]())
atomic {
val users = ref.get
val newUsers = users + ("bill" -> User("bill")) // creates a new HashMap
ref.swap(newUsers)
}
atomic {
ref.get.apply("bill")
}
// -> User("bill")
Here is the same example using TransactionalMap:
import akka.stm._
case class User(name: String)
val users = TransactionalMap[String, User]
atomic {
users += "bill" -> User("bill")
}
atomic {
users("bill")
}
// -> User("bill")
Persistent datastructures
Akka’s STM should only be used with immutable data. This can be costly if you have large datastructures and are using a naive copy-on-write. In order to make working with immutable datastructures fast enough Scala provides what are called Persistent Datastructures. There are currently two different ones: * HashMap (scaladoc) * Vector (scaladoc)
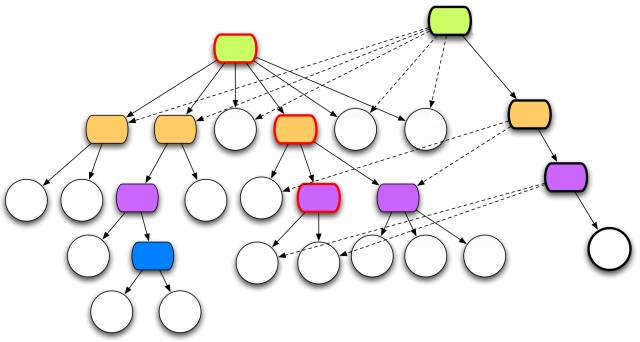
They are immutable and each update creates a completely new version but they are using clever structural sharing in order to make them almost as fast, for both read and update, as regular mutable datastructures.
This illustration is taken from Rich Hickey’s presentation. Copyright Rich Hickey 2009.
Ants simulation sample
One fun and very enlightening visual demo of STM, actors and transactional references is the Ant simulation sample. I encourage you to run it and read through the code since it’s a good example of using actors with STM.
Contents
